Reducing Risk by Deleting Code
One of my favorite activities as a software professional is to delete code. Over time, I’ve learned that this is one of the best things I can do because the ideal amount of code is no code at all.
If you can deliver value without writing any code, you avoid the development and maintenance costs. And there won’t be any software bugs! A fantastic example of this comes from Pragmatic Dave Thomas1. A company was having problems with their mail not getting to the right departments. They wanted a complex OCR system for routing their mail, but he suggested they could just use colored envelopes instead. No code was needed and the company saved a lot of money.
Code is a Liability
Of course, we do need some code because software can deliver incredible value. But that value comes from what the code does or enables. Code isn’t intrinsically valuable. Rather it is a liability.
Once you have code, the developers need to understand it. It needs to be updated when requirements change. It may have bugs. These things bring risk and can slow a software business down. Even the most perfect code can become problematic when the world changes around it. Changes to languages, frameworks, paradigms, or operating systems can add a burden to otherwise good code.
Since we need code, we need to manage the risk. I have found that the two biggest things software developers can do are:
- improve code quality
- manage the size of the codebase
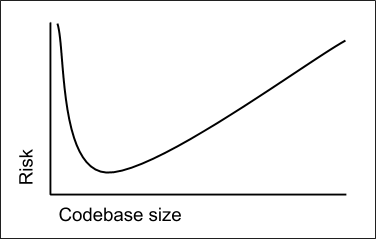
Code quality and the codebase size are highly correlated. Having too much code lowers software quality as it becomes harder to understand and manage the sheer size. You literally have to pay for your excess. On the other hand, quality also suffers if you have too little code. Either there isn’t enough code to deliver the needed value or the code becomes needlessly difficult to read and maintain.
The right amount of code is an optimization problem. Generally speaking, you want your codebase to be small relative to the feature value you provide, but not so small that you start violating good design principles.
Delete Code
In most codebases there is a lot of room to improve quality and reduce risk by deleting code. You have to be disciplined in how you delete though. It’s important to preserve the value that the software is delivering. Luckily there is a well-known technique to help with this2:
Refactoring (noun): a change made to the internal structure of software to make it easier to understand and cheaper to modify without changing its observable behavior.
Code refactoring should be used to keep your quality high and size small. It can be done while writing code (I prefer to do it continuously as an integral part of the Test Driven Development loop) or it can be done to improve existing code.
Unfortunately, not all code provides value. Some features just aren’t used enough in the software to justify their existence. They should be deleted. Worse still, “dead” code lurks in many codebases, distracting and confusing developers while never being executed.
Lean and Mean
Lean software development recognizes that code is a form of inventory, and therefore potential waste. So slim down! Get rid of the excess! Like an exercise regimen, it won’t be easy but the results speak for themselves.
I particularly like this quote on the subject from Michael Feathers:
I think that the future belongs to organizations that learn how to strategically delete code. Many companies are getting better at cutting unprofitable features in their products, but the next step is to pull those features out by the root: the code. Carrying costs are larger than we think. There’s competitive advantage for companies that recognize this.
Refactor code to maximize the good and reduce the bad. Mercilessly delete code that isn’t providing value!
-
I heard this story related by Neal Ford on the SE-Radio podcast (32 minutes in). ↩
-
This definition of the term “refactoring” comes from Martin Fowler’s bliki. He literally wrote the book on it. ↩