Scaling Experimentation Part 2: Buy vs Build
See the first post in this series here
Welcome back! As mentioned the first post, the product org at Pluralsight has determined to skill-up the data driven portion our product development process. We’ve long had a robust way of incorporating qualitative user input via Directed Discovery—we’ve now prioritized helping our cross-functional development teams gather data on how their efforts are impacting metrics important to the business.
At the end of the previous post, we identified needs for an experimentation platform. Specifically, we determined that there were several initiatives needed to build a culture of experimentation.
Needs -> Solutions
- Just let me test -> Easy testing on both the client- and server-side
- Metric clarity -> Rigorous and standard analysis for our key metrics
- Can I find that research -> A central knowledge repo of results
In this post, we explore build vs buy options, and describe how we’re combining third-party solutions with a small in-house minimum viable product-style (or MVP-style) build to address experimentation needs. But first, let’s step back. Web experimentation originally was the realm of marketers and conversion optimization teams looking to increase users signing up for a trial, making a purchase, or just submitting a web form.
Since these first experiments were based around design changes on a single page, client-side (or JavaScript-based) tests were standard and are still popular today. Essentially, there’s a WYSIWYG that lets one easily change page elements like typography, copy, arrangement, etc without the help of a software engineer. Then the difference between A and B is served in the user’s browser.
As web experiences became more algorithm-driven via features like search and recommendations, server-side tests became more common because differences in solutions must be served from the web server itself. While server-side tests are offered via feature flags and require work from engineers, client-side solutions let product managers and designers launch tests via a WYSIWYG editor.
As mentioned, many Pluralsight product managers (PMs) expressed a critical need to experiment quickly, and both client- and server-side testing would be required since much of the Pluralsight experience is data-driven. To address that need as well as the need for rigorous analysis and a central knowledge repo to house results, a classic conundrum arose: do we build or buy? One of our favorite frameworks in this space is by Kent McDonald and Neil Nickolaisen, called the Purpose-Based Alignment Model, which is presented in their book Stand Back and Deliver: Accelerating Business Agility.
The framework states that if something can be a market differentiator and is core to the business, then it’s a particularly good time to own that expertise in-house and build a solution that fits the company’s particular needs. At Pluralsight, data-driven product development is core to our business and a market differentiator, which indicates that building and owning that expertise in-house makes sense. Nevertheless, there are compelling A/B testing tools we were interested in exploring. Even if you ultimately build the solution yourself, talking to vendors sharpens your thinking.
Vendor Assessment
As part of the discovery process, we vetted two main vendors in this testing space with help from our architecture, data science, and product analyst teams: Optimizely and Adobe Target. Optimizely has two main products, Web and Full Stack, which provide tooling around client-side and server-side tests, respectively. We have many colleagues who had leveraged their tools in the past, they have a respected stats engine, and provide a premium product that can cost above $100k per year. They were impressive to work with and their product had many features we liked—test planning, early stopping, polyglot SDKs, and a randomization procedure that doesn’t require http calls.
At Pluralsight, our user click-stream data is gathered via Adobe Analytics (AA). Pluralsight has invested heavily here over the last two years, such that we can now broadly understand user behavior across the app. This is where difficulties with the Optimizely solution arose. Since we wanted their stats engine to process metrics based on our AA data, this integration was critical. What we found was that their engine was able to process event-based metrics like assessments taken and authors followed, but doesn’t have the ability to report on sessions, visits, or judge tests by time-frame-based retention metrics. This means that we couldn’t use Optimizely and also prioritize metrics like user retention, visits per visitor, and content time consumed, which are critical to evaluating our user experience. The uncertainty around the time and technical investment needed to make this work was too much to bear.
Note that this may be a lesson for those SaaS product folks out there running experiments. Historically, testing solutions were focused on the client-side and marketing event-based metrics like conversion. While it’s becoming more common for vendors to focus on server-side solutions and SaaS metrics around user retention, we found the third party offerings there are much less robust.
The other vendor we vetted closely was Adobe Target, which has been deployed and loved in our marketing department. Here the Adobe Analytics integration is easy, in that any metric and segment you work with in AA can be used to judge tests in Adobe Target. On the client-side, as with most offerings, the Target WYSIWYG editor makes it easy to manipulate web elements like typography and quickly deploy A/B tests on a desired percentage of users.
On the server-side, however, Adobe Target was less appealing. While they had been investing in their server-side offering, it relies on http calls to randomize users into A vs B experiences. In other words, a Pluralsight web server must reach out via an http request to an Adobe server to determine the assignment of a particular userhandle to variant A vs B.
These sort of http calls give us heartburn from an engineering reliability perspective. It’s critical to PS that the user experience rely on as few third-party dependencies as possible (so that we can avoid associated downtime and response times). Because of this, any new vendor with such a requirement immediately faces a stiff headwind. Upon further investigation, Adobe Target’s server-side response times were unacceptable to our user experience. We determined, however, that the WYSIWYG client-side tooling from Adobe Target would be beneficial in that it would enable our product managers and designers to quickly create experiments, especially since many setup hurdles had already been surmounted by its long-time use in our marketing org.
Overall Technical Solution
None of the vendor solutions alone met our needs, so we decided on a mix of current tooling and small build investments to help scale experimentation across the product org. Rather than immediately forming a product experience team to build out a holistic solution, we’ll instead focus on an MVP and collect quick feedback on what works. Here we’ll focus on describing the solutions related to 1) the randomization into A vs B; 2) the stats engine that will provide standard and rigorous analyses; and 3) Experiments HQ itself, which will provide internal users the ability to quickly review the progress of their live tests and learn from past test results across the org.
Randomization and Tracking
Fundamental to rigorous A/B testing is the randomization procedure, which allows one to create robust control and treatment groups that are evenly distributed across various user attributes. For example, there are some users that heavily use our notes feature when using Pluralsight—for most experiments, we don’t care about notes specifically, so an effective simple randomization will have a representative distribution in the control and treatment groups of users that do and do not use notes. A good randomization tool also provides the ability to select users for the experiment overall by userhandle or criteria.
On the server side, LaunchDarkly has been our feature flagging tool of choice for product rollouts for over a year. It has several nice features that make it appropriate for server-side testing:
- Allows us to easily randomize users into control vs test groups for web and mobile
- Provides controlled rollouts independent from targeting
- Offers polyglot SDKs, essential for our polyglot teams
- Doesn’t require http calls to LaunchDarkly servers because the SDK, if you’re using it, relies on its stored state to evaluate flags
On the client side, Adobe Target provides several benefits:
- Allows us to quickly manipulate web elements like typography, styling, colors, and layout
- Lets PMs and designers launch tests without engineering resources
- Offers specific test targeting to particular AA user segments (like users who have done X)
Adobe Target, like LaunchDarkly, will be used primarily for the jobs of selecting users into experiments, and assigning them into specific test groups.
To make sure that these experiments are tracked coherently from an Adobe Analytics perspective, the product analytics team has developed an experimentTrack method, which is a Javascript event that is listened for by our tag management system, which then executes tracking on the experiment into several of our data processing systems. This makes it such that AA not only captures standardized cross-app data on user behavior after entering an experiment, but also data on who was assigned to which experiment group. While some of this tracking could be done in developer databases, the autonomous nature of our teams (and the fact that each team stores data in their own database) would require a much larger investment to achieve our experimentation goals.
Despite the fact that 5-8% of our users block web analytics tools with their browsers, our current implementation of Adobe Analytics gives us standardized data across all parts of the app, and provides enough data to make significant conclusions around the PS user population overall. Having this standardized data collection through AA allows us to run an A/B test in one corner of the app and measure that test’s influence on follow-up user behavior across the app. Because of this, and while the v1 solution isn’t perfect, we’re routing all experiment data via Adobe Analytics.
The Stats Engine
While there are various approaches to A/B experiment statistics, we’re going to start simple and focus on frequentist stats with fixed-length tests. While Bayesian methods and sequential hypothesis testing provide some intriguing benefits, considering our other low-hanging fruit, we’re going to start simple from a stats perspective. Once these data pipelines are in place and we’ve gotten feedback on this first iteration, we’ll be open to switching out our analysis framework.
The first version of the stats engine will be based on a Python repo, backed by unit tests and continuous integration, which is deployed via docker and produces results every hour. Overall, the engine will provide standard ways of preprocessing the data, defining metrics, and computing the results of the test. Overall, it provides several benefits:
- Common definition of metrics
- Standardization of experiment analysis
- Reproducibility of the analysis
- Visibility into the process
The engine is tasked with assessing all product A/B tests by one of a few core metrics. For much of our org, that will be user retention.
Note that LaunchDarkly doesn’t provide user behavior analytics after the user traverses the feature flag and Adobe Target doesn’t provide robust retention metrics either, so the stats engine will provide experiment insight and standardization across both client- and server-side tests. While product experience teams can view and contribute to the stats engine code in github, the primary way users will interface with the stats engine is via an internal website.
Experiments HQ
In the first post in this series we highlighted the fact that PMs and their teams struggle to find insight into experiments while their test is live and after the test has ended. In the past, Adobe Analytics workspaces had been used in stop-gap way, but this typically was the result: ”Okay, I see that visits per visitor is higher for B compared to A, but is that significant?” These product teams also struggled to find past quantitative research from other teams that was quickly digestible. To help solve this, we’re building an MVP of an experiments platform that will function as experimentation HQ. The first version will essentially be a dashboard presenting results of all experiments in a standard way, accessible via an easily-accessible internal domain.
While we had contemplated doing this in Tableau, we decided to start via a web app, such that we have maximum flexibility and can eventually hand this off to a dedicated product experience team. At first, this web app will be used for presenting standardized results for both live and concluded tests, and will act as a knowledge repo in that it centralizes and formats all test documentation. Eventually, however, this platform will take on more and more of the experimental workflow (i.e., collecting test details, guiding metric choice, alerting when tests reach significance, etc) via a transactional database dedicated solely for that purpose.
Figure 1: An early mockup of the experiments platform
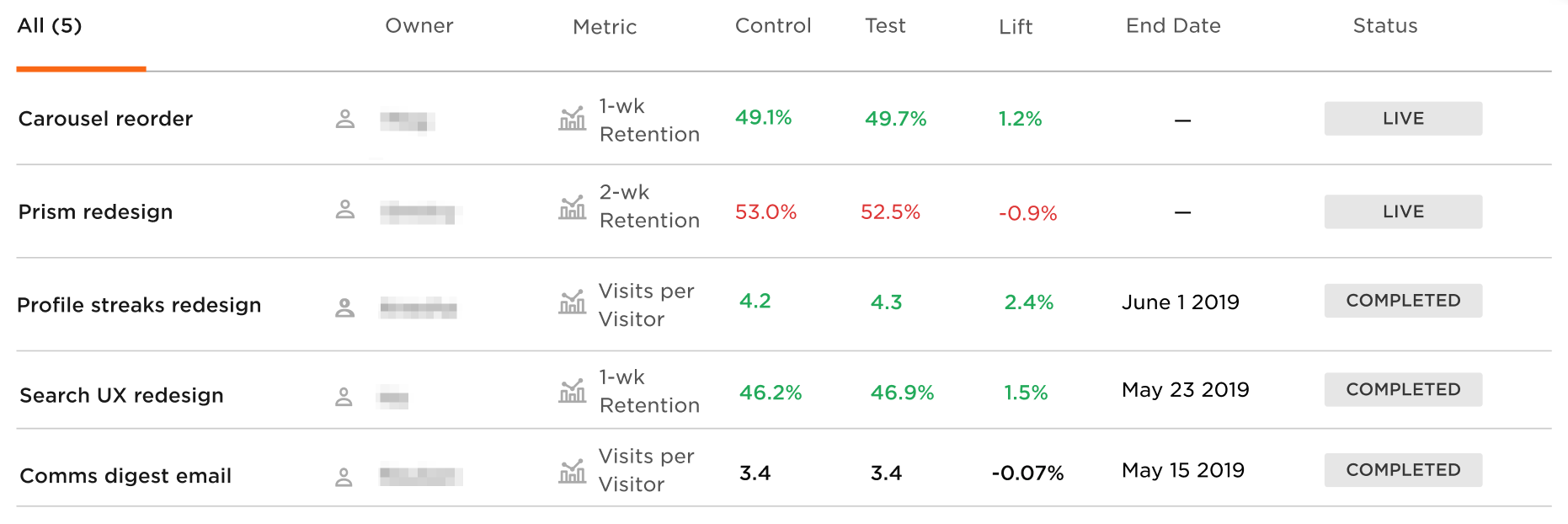
Overall, the skateboard of our home grown solution will include LaunchDarkly for server-side tests, Adobe Target for client-side tests, Adobe Analytics for web analytics, a home-grown stats engine, and a centralized experiments platform built in a web app.
We should reiterate that the goal of this project is to build a culture of experimentation and make it easier for product teams to experiment safely, quickly, and in a rigorous way. Outside of the technical priorities we’ve described above, there is significant cultural piece to this project, which we’ll dedicate to a future post. In the meanwhile, happy testing!