Disaster Recoverable Data Persistence with Apache Cassandra - Prepare for the Unexpected
See how proper cluster deployment and replication configuration with Apache Cassandra can ensure the integrity of your enterprize's data when disaster strikes.
Dec 15, 2018 • 18 Minute Read
Introduction
That you're reading this article tells me something about you.
To begin with, it tells me you have come to the understanding that your data is most important to you. It also tells me that you have enough experience and maturity to admit the fact that nothing can be accepted without being challenged.
When it comes to data management, most platforms will make promises about their data integrity.
However, being the responsible professional you are, would you risk your business on the mere promise that "once you’ve migrated to this technology, your data will be (safe/secure/etc.)”? Some might, but again - if you’ve got to read this article, that “some people” is not you. You know better. When talking about data integrity, I refer to the factors of data accuracy and data consistency.
Under most circumstances, you - the technology user - would be correct to assume that neither data accuracy nor data consistency are free.
In order to maintain data accuracy, for example, you have to make sure that a specific data insertion request did not (undesirably) overwrite previously stored data.
Algorithmic correctness is mandatory when working against your data layer, with any technology. No technology will fully protect you from an evil bug. Algorithmic correctness will help you achieve logical integrity of your data.
Once you’ve got logical integrity out of the way, you will now enter the domain of physical integrity.
Reaching a high physical integrity of your data means that you have given thought to the challenges related to working with hardware devices, computer networks, network domains, servers and actually anything physical your data relies on.
In general, the most common way to tackle physical integrity is by using a distributed architecture. Distributed architectures come in various flavours, sizes and shapes. Most of them have a sort of a redundancy mechanism. Some have the notion of data replication.
In this article, I would like to review the concept of physical data integrity with Apache Cassandra, a most popular distributed database technology that I’ve had the pleasure of using.
If you want a more basic overview of Apache Cassandra, before you dive into the article, I’ve written a dedicated module about it in my latest course. Feel free to check it out here.
Let's get started!
A Word About Apache Cassandra
Apache Cassandra is a NoSQL, distributed database. With this simple statement we’ve described both deployment model (distributed as opposed to centralized) and data model (non “standard” relational, tabular data).
We’ve already mentioned in the introduction that physical integrity of data might be challenged by physical malfunctions in hardware. Taking on a distributed approach, statistically reduces that risk. Via the deployment of multiple physical resources (e.g. hosting servers, storage arrays) and “placing” our software layer (in our case, this software layer in an Apache Cassandra cluster) on top of it, will be of benefit. But …
The amount of benefit is subject to change and is dependent of several factors.
The first factor is that we’ve introduced relevant additional physical resources.
An Apache Cassandra cluster is made out of nodes. These nodes are basically processes running on a host machine, contributing their capabilities to the cluster.

These nodes can be grouped under logical data centers and racks, as a matter of simple configuration.

Why am I emphasizing the word “relevant” when discussing physical resources and the word “logical” when discussing proper grouping of nodes in our cluster? Let me tell you a true story.
Case Study
I’ve developed a data layer for a client, on top of Cassandra (I will omit the “Apache” prefix from now on, though throughout this article I am talking about the Apache Cassandra version of Cassandra).
My client requested for Cassandra to be hosted in docker containers, so I created a relevant docker image, which can receive configuration parameters once a container is being instantiated based on it.
I’ve made sure to create relevant config files for the nodes in the Cassandra cluster.
I handed it over to the DevOps team, the cluster was brought up and all were happy. Dangerously and very mistakenly happy.
Apparently - and this was absolutely my responsibility to make sure this doesn't happen - the DevOps team created the entire cluster on a single host machine.
Now, it was a “strong” host machine, with a dedicated core per Cassandra node, plenty of RAM, and blazing fast storage. But it was a cluster, a distributed technology, deployed on a single machine. A single point of failure! Any power outage or catastrophic hardware failure of the hosting machine could have ended in downtime and data loss, defeating the purpose of Cassandra's distributed capabilities.
Things Can and Will Go Wrong
Before we dive in and explain what could have been done better, let’s talk about how things tend to go wrong at some point.
When talking about a Cassandra cluster, what are our main resources?
Our nodes are deployed as processes on hosting machines. Then, each process manages it’s own data files, right? In conclusion, each process communicates with other nodes, through a network interface.
There are obviously other resources, such as RAM, but those I’ve mentioned are sufficient for me to make my point.
In general, we have the hosting machine, the internal resources it uses to perform data management tasks, and the resources required to communicate with the rest of the cluster.

Now, there are several situations in which any one (sometimes more than one) of these machines, their internal resources or their abilities to communicate with the cluster gets hindered.
It is our responsibility to make sure our data layer can withstand a fatal problem in any of these situations.
Preparation Is Key
“You hit home runs not by chance but by preparation.” - Roger Maris
With centralized databases, most of what was considered as preparation for a disaster is based on backups and reliance on relatively reliable storage devices.
Some systems took on other approaches, such as running two separate database instances, and in case of a failure in one of them - the system had the other one to rely upon.
However - this approach has a very high overhead, doesn’t it? Each instance is a full-blown database, operating as if it was the sole system database. Moreover, no instance we add to the system, in such a deployment, contributes to the systems ability to process any more data. This is troubling because we are adding high cost resources while getting … the same performance? Can’t we do better?
Indeed, we can.
With Cassandra, each node, aside just building up the overall integrity of our stored data, increases our systems bandwidth - talking about data, of course.
But some of this bandwidth depends on some prior preparation.
And that preparation is mostly by considering the way we deploy our cluster. By giving thought to the manner in which we configure our cluster nodes, we can increase our system's ability to maintain its data integrity under very bad situations (hardware failure wise).
Choosing how we spread our nodes across logical racks and data centers - as well as across physical racks and data centers, will make a difference.
Deployment Considerations
Node Naming - Be Consistent
“I accept chaos, I’m not sure whether it accepts me.” - Bob Dylan
When planning your cluster, I highly recommend using consistent, meaningful names for your Cassandra nodes. Choose a naming convention, which reflects, at least:
- Data center name
- Rack name
- Node Id
Be brief and concise, with your node names, as you will need to use them in configuration files.
For example, how about the following proposed structure:
DC<datacenter id>Rack<Rack id>Node<Node id>
So if we have four nodes in each data center, two in each rack, we will have
DC1Rack1Node1
DC1Rack1Node2
DC1Rack2Node1
DC1Rack2Node2
DC2Rack1Node1
DC2Rack1Node2
DC2Rack2Node1
DC2Rack2Node2
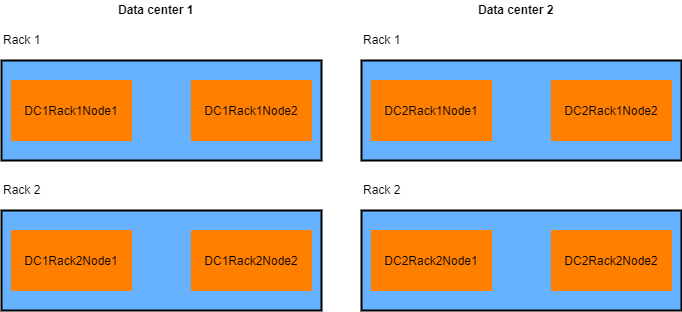
Now, this touches upon something that should be trivial, but at the same time something that I encountered in surprising situations. make sure the logical names reflect the physical deployment. There is no sense, in naming a node which physically resides on data center x and rack y “DCxRackz”, right?

Use a Correct Partitioner
A Partitioner is an algorithm which is responsible for replica distribution among the cluster nodes.
For performance reasons, you should make sure replicas are distributed in a uniform manner across your cluster.
However, using an incorrect (e.g. custom) partitioner might hinder the distribution of replicas across your cluster in a manner that might even affect your disaster recoverability.
Using a proven, out of the box partitioner, such as the Murmur3Partitioner, is highly recommended.
Use a Proper Replication Strategy
A replication strategy is, as the name suggests, the manner by which the Cassandra cluster will distribute replicas across the cluster.
When your cluster is deployed within a single data center (not recommended), the SimpleStrategy will suffice.
However, when moving to a multi data center deployment, please make sure to use the NetworkTopologyStrategy, which will allow for the definition of desired replication across multiple data centers.
I personally recommend using the NetworkTopologyStrategy in any case. Be prepared.
Rack Aware Cluster Configuration - Be Efficient
In-rack node communication is very efficient.
You might be tempted to deploy your entire cluster to the same data center server rack. Don’t.
A server rack is a point of failure. Power outages, fire, or just plain old maintenance might cause an entire rack to become offline.
As a general rule, use at least two different server racks on each data center.
Make sure to distribute your Cassandra nodes evenly, among your racks (Assuming each rack has the same hardware resources).
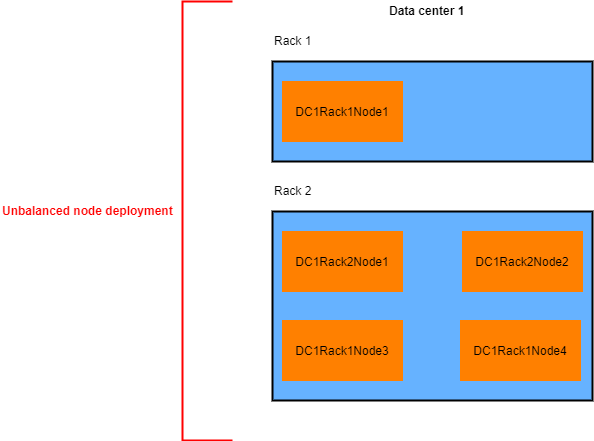
Use a rack aware snitch.
A rack aware snitch will make sure that the Cassandra cluster is aware of each node's physical location and can distribute replicas across racks accordingly.
But is configuring a rack aware snitch sufficient to make sure our data is properly replicated among server racks? No. Something is missing.
That something is a proper configuration value of the replication factor defined at the keyspace level.
Choosing the correct replication factor could be confusing at first because setting a replication factor is not orthogonal to other configuration parameters, such as write level (the number of replicas that need to acknowledge a write operation) and read level (the number of replicas that need to acknowledge a read operation).
A good practice would be to make sure your write level when added to the read level is larger than your replication factor.
So, in a cluster made of 4 nodes, spread across 2 racks, given a write level of 2, and a read level of 1, you will need to make sure your replication factor is larger than 3.
This setting actually means that you can suffer the loss of up to (any) two nodes without any downtime to your application!
Now, assuming you’ve heard my advice and properly distributed your nodes across your available racks, you can “suffer” any rack going down without losing data / availability time.
While we achieved this with an inherent overhead (all of our nodes are storing 100% of our data) - we’ve made sure we can “stay alive” in the scenario of a failed server rack!
As I’ve mentioned before, your cluster size (node count), replication factor, write consistency and read consistency are not orthogonal. A change to one, might have an impact on how your cluster behaves, both performance wise and consistency wise.
Make sure you read and understand the mentioned parameters from the problem above and adjust them properly to your use case.
I’ve seen deployment done “by the book”, when it comes to spreading nodes and defining all relevant replication parameters correctly only to discover that all nodes use the same storage device.
Even if you are using a top notch network storage device, with raid arrays, please don’t share the same storage hardware across nodes or racks.
Even the best storage arrays will suffer from malfunctions, eventually. Sharing them among nodes means that a single malfunction will cause more than one node to become unavailable.
When discussing node storage, in a Cassandra cluster - I highly recommend using local storage. You can protect your local node storage by using raid - just make sure you work locally.
Please notice that I am not saying that network storage is bad. Use it, if that is what you prefer. Just make sure every storage resource you are using is local to a single Cassandra node.
Data Center Aware Cluster Configuration - Be Paranoid
Multiple racks are great, but not enough.
It is not a fictional assumption to assume that an entire data center might go offline. It happened in the past for the largest companies and cloud providers. It is a matter of time before it happens again. If you care about your data and your users remaining online under such circumstances - be responsible and make sure your cluster is (properly) deployed across multiple data centers.
Doing so with Cassandra is not only possible but also rather simple to configure.

What you’ve learned up to this point will serve you well. You already know that you need to distribute your data in a uniform manner across your cluster. And you understand that this will mostly be done by choosing a proper partitioner. I’ve recommended the Murmur3Partitioner.
You also understood that it is of importance to let your cluster be aware of the network topology it resides in, using the NetworkTopologyStrategy snitch.
In Cassandra, the replication factor is defined per keyspace and data center.
That means, that we can (and usually will) define a different replication factor per each datacenter.
For disaster recovery purposes, it is very common to have a data center dedicated for the purpose of replicating data “online” and “waiting” for a catastrophe to happen.
In such a case, this data center will “take on” and serve existing users.
There are several practices when regarding multiple data centers.
Some prefer placing different data centers at different geographical zones, having each data center nodes serve “local” users while replicating their data to remote nodes.
Others, prefer having all nodes serve all users, letting Cassandra decide which node serves which user.
These practices are mostly relates to performance matters and I might touch these in a future article, as per your request.
My personal recommendation, and some people have a different opinion, is not to treat one data center as a “main” datacenter and the other as “disaster recovery” datacenter, and assign each different resources. Try to scale them similarly and replicate your data with the same replication factor on each.
This will have a larger overhead of nodes and storage - and it is your decision how to balance the cost of overhead with the possible cost of data loss.
In Conclusion
In this short article, I’ve tried to emphasize the importance of proper Cassandra cluster deployment and replication configuration so that your enterprizes data remains integral and available when disaster strikes.
With hardware devices, it is only a matter of time prior to failure, and in today's “always-on” user demands, you can probably not allow your system to become neither.
By proper deployment of your cluster nodes, in a balanced manner, across server racks and data centers - and complementing the deployment with a generous replication policy - you will be able to meet these demands.
As previously mentioned, this article favours disaster recoverability over performance.
As with anything in life, a proper balance should be met, and your scenario might be the other way around. In such a case, you will find out that mostly the same parameters we’ve discussed in this article come to play again, and with proper tuning of them - you will be able to achieve your goal.
I hope you’ve enjoyed this article and thank you for joining me in this short journey towards understanding disaster recoverability with Apache Cassandra.
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
