Interactive Queries on Hadoop with Presto
Presto is an interactive in-memory query engine with an ANSI SQL interface. This guide covers its benefits and how to run distributed in-memory queries.
Oct 5, 2020 • 4 Minute Read
Introduction
Batch processing has been the go-to use case for big data for decades. However, recent years have seen the rise of and need for interactive queries and analytics. Both traditional and modern batch processing frameworks fail to address the need for low-latency queries through a familiar yet useful interface.
Presto is an interactive in-memory query engine with an ANSI SQL interface. This guide will explore the benefits of the Presto query engine and how to run distributed in-memory queries in a Hadoop environment. The contents assume prior knowledge of the Hadoop ecosystem and the Hive Metastore.
Presto Architecture
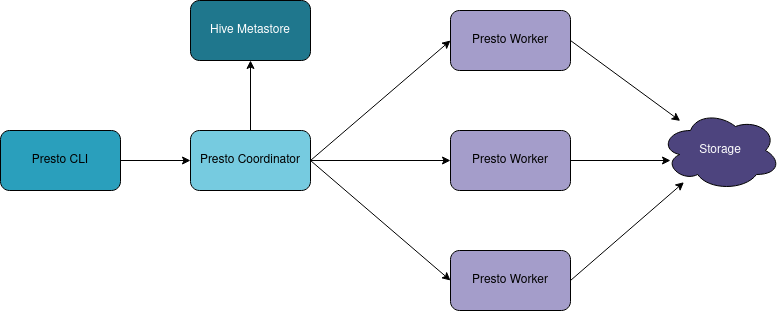
Like most big data frameworks, Presto has a coordinator server that manages worker nodes. The Presto Coordinator needs to connect to a data catalog, normally HCatalog, built on top of the Hive Metastore. The Hive Metastore will contain the data schema information.
The workers will take care of reading data to and from the data store, whether it's S3, HDFS, or other compatible data stores. The operations are all executed in memory, and if the cluster runs out of memory then the job will fail by default with an Out of memory error. The in-memory execution will allow the queries to run and return the results incredibly quickly. The general rule of thumb is that the whole dataset you are analyzing should fit into memory.
Running Queries in Presto
To run queries using presto, you first need to create a Hive table. The following snippets are taken from the SQL on MapReduce with Hive guide.
Create the Hive Table
Start a beeline session to connect to Hive.
beeline -u jdbc:hive2://<ip>:10000/ -n <username>
Afterwards, create a table that points to your data source.
CREATE EXTERNAL TABLE amazon_reviews_parquet(
marketplace string,
customer_id string,
review_id string,
product_id string,
product_parent string,
product_title string,
star_rating int,
helpful_votes int,
total_votes int,
vine string,
verified_purchase string,
review_headline string,
review_body string,
review_date bigint,
year int)
PARTITIONED BY (product_category string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amazon-reviews-pds/parquet/'
Finally, have Hive automatically identify the data partitions.
Start and Interactive Presto Session
To connect presto to Hive, all you need to do is run the CLI client and specify that you are using the hive data catalog.
presto-cli --catalog hive --schema default
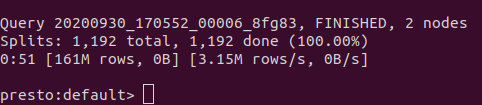
Afterwards, you can run your query in an interactive shell prompt. To showcase the difference in query latency, this image shows the following query SELECT product_category, COUNT(*) FROM amazon_reviews_parquet GROUP BY product_category; run on Hive. The query takes approximately 30 minutes to complete using the Hive execution engine.

This is the benchmark for the query run on Presto. The query takes less than a minute to obtain the same results.
Conclusion
Presto enables interactive querying on a large dataset. You write a query and get a result far more quickly than with other tools. However, speed comes at a price. The requirement that your entire data set fits in memory can make Presto an expensive tool to deploy. Most users therefore use Presto in managed service environments such as Amazon Athena or Azure Starburst Presto.
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
