The quest for availability in the cloud
There are three important ways how can you reconcile both cloud availability and velocity for the greater good of your customers. Learn More!
Jun 08, 2023 • 11 Minute Read

How many nines of happiness are your customers?
In this series of posts, I will walk you through architecting, building and deploying a large scale, multi-region, active-active architecture — all while trying to break it.
The idea is to split the series into the following structure:
- The Quest for Availability
- How to build a multi-region active-active architecture on AWS
- Building a Multi-Region, Active-Active Serverless Backend
- Building a Multi-Region, Active-Active Serverless Backend — within a VPC
- Multi-Region reloaded: Accelerating Serverless Applications with Global Accelerator and Application Load Balancer
Of course — the structure might and probably will change as I continue writing and get your feedback, so feel free to steer the course of (t)his (s)tory in the comments below :)
System failure
One of my favorite quotes that influenced my thinking of software engineering is from Werner Vogels, CTO at Amazon.com.
“Failures are a given and everything will eventually fail over time.”
Indeed, we live in a chaotic world where failure is a first-class citizen. Failure usually comes in three flavors; the early failures, the wear-out (or late) failure, and the random failures — with each coming at a different stage in the life of any given system.

Early failures are essentially related to programming and configuration bugs (typos, variable mutations, networking issues like ports and IP routing misconfiguration, security, etc…). Over time, as the product (or version) matures and as automation kicks-in, those failures tend to naturally diminish.
Note: I just mentioned “automation kicks-in”! This really means that you have to be using automation to experience this natural declining behaviour of early failures. Doing things manually won’t allow for that luxury.
Wear-out (or late) failures — you often read online that software systems, unlike physical components, are not subject to wear-out failures. Well, software is running on hardware, right? Even in the cloud, software is subject to hardware failure and therefore should be accounted for.
But that’s not all, wear-out failures also and most often are, related to configuration drifts. Indeed, configuration drift accounts for the majority of reasons why disaster recovery and high availability systems fail.
Random failures are basically, well, random. A squirrel eating your cables. A shark brushing its teeth on transatlantic cables. A drunk truck driver aiming at the data-centre. Zeus playing with lightings. Don’t be a fool, over time, you too will eventually fall victim to ridiculous unexpected failures.
The velcocity of innovation
We live in a environment where velocity is critical — and by that, I mean being able to deliver software continuously. To give you an idea of velocity at scale, Amazon.com, in 2014, was doing approximately 50 million deployments a year, that’s roughly 1.6 deployments per seconds.
Of course, not everyone needs to do that — but the velocity of software delivery, even at smaller scale, does have a big impact on customer satisfaction and retention.
So how does velocity impact our “bathtub” failure rate curve? Well, it now looks more like the mouth of a shark ready to eat you raw. And indeed, for each new deployment, new early failures will be thrown at you, hoping to take your system down.

As you can easily notice, this creates a tension between the pursuit of high availability and the speed of innovation. If you develop and ship new features slowly, you will have a better availability — but your customer will probably seek innovations from someone else.
On the other hand, if you go fast and innovate constantly on behalf of your customers, you risk failures and downtime — which they will not like.
To help you grasp what you are fighting against, I included the table of “The Infamous Nines” of availability. Let that table sink in for a minute.

If you want to have 5-nines of availability, you can only afford 5 minutes of downtime a year!!
Few years ago, I experienced first-hand a complete system meltdown. It took our team few minutes just to realize what was happening, another few minutes to get our sh*t together and slow our heart-rate down, and another couple hours to complete a full system restore.
Lesson learned: If __any__ humans are involved in restoring your system, you can say bye-bye to the Infamous Nines

Availability vs Reliability with AWS
So how can you reconcile both availability and velocity for the greater good of your customers? There are three important things, namely:
- Architecting highly reliable and available systems
- Tooling, automation and continuous delivery
- Culture
Simply put, what you should aim for is having everyone in the team confident enough to push things into production without being scared of failure.
The best way to do so is by first having highly available and reliable systems, having the right tooling in place and by nurturing a culture where failure is accepted and cherished. In the following, I will focus more on the availability and reliability aspect of things.
It is worth remembering, that generally speaking a reliable system has high availability — but an available system may or may not be very reliable.
What is availability in the cloud?
Consider you have 2 components, X and Y, respectively with 99% and 99.99% availability. If you put those two components in series, the overall availability of the system will get worse.

It is worth noting that the common wisdom “the chain is as strong as the weakest link” is wrong here — the chain is actually worsened.
On the other hand, if you take the worse of these components, in that case, A with 99% availability, but put it in parallel, you increase your overall system availability dramatically. The beauty of math at work my friends!

What is the take away from that? Component redundancy increases availability significantly!
Note: you can also calculate availability with the following equation:

Alright, now that we understand that part — let’s take a look at how AWS Regions are designed.
AWS Availability Regions and Availability Zones
From the AWS website, you can read the following:
The AWS Cloud infrastructure is built around Regions and Availability Zones (“AZs”). A Region is a physical location in the world where we have multiple Availability Zones. Availability Zones consist of one or more discrete data centers, each with redundant power, networking and connectivity, housed in separate facilities.
Since a picture is worth 48 words, an AWS Region looks something like that.

Now you probably understand why AWS is always, always talking and advising its customers to deploy their applications across multi-AZ — preferably three of them. Just because of this equation my friends.
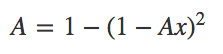
By deploying your application across multiple AZs, you magically increase, and with minimal effort, it’s availability.

This is also the reason why using AWS regional services like S3, DynamoDB, SQS, Kinesis, Lambda or ELBs just to name a few, is a good idea — they are by default, using multiple AZs under the hood. And this is also why using RDS configured in multi-AZ deployment is neat!
The price of availability
One thing to remember though is that availability does have a cost associated with it. The more available your application needs to be, the more complexity is required — and therefore the more expensive it becomes.

Indeed, highly available applications have stringent requirements for development, test and validation. But especially, they must be reliable, and by that, I mean fully automated and supporting self-healing, which is the capability for a system to auto-magically recover from failure.
They must dynamically acquire computing resources to meet demand but they also should be able to mitigate disruptions such as misconfigurations or transient network issues.
Finally, it also requires that all aspects of this automation and self-healing capability be developed, tested and validated to the same highest standards as the application itself. This takes time, money and the right people, thus it costs more.
Increasing availability
While there are tens, or even hundreds of techniques used to increase application reliability and availability, I want to mention two that in my opinion stand-out.
Exponential backoff
Typical components in a software system include multiple (service) servers, load balancers, databases, DNS servers, etc. In operation, and subject to potential failures as discussed earlier, any of these can start generating errors.
The default technique for dealing with these errors is to implement retries on the requester side. This simple technique increases the reliability of the application and reduces operational costs for the developer.
However, at scale and if requesters attempt to retry the failed operation as soon as an error occurs, the network can quickly become saturated with new and retired requests, each competing for network bandwidth — and the pattern would continue forever until a full system meltdown would occur.
To avoid such scenarios, exponential backoff algorithms must be used. Exponential backoff algorithms gradually decrease the rate at which retries are performed, thus avoiding network congestion scenarios.
In its most simple form, a pseudo exponential backoff algorithm looks like that:

Note: If you use concurrent clients, you can add jitter to the wait function to help your requests succeed faster. See here.
Luckily many SDKs and software libraries, including the AWS ones, implement a version (often more sophisticated) of this algorithms. However don’t assume it, always verify and test for it.
Queues
Another important pattern to increase your application’s reliability is using queues in what is often called message-passing architecture. The queue sits between the API and the workers, allowing for the decoupling of components.

Queues give the ability for clients to fire-and-forget requests, letting the task, now in the queue, to be handled when the right time comes by the workers.
This asynchronous pattern is incredibly powerful at increasing the reliability of complex distributed applications — but is unfortunately not as straightforward to put in place as the exponential backoff algorithms since it requires re-designing the client side. Indeed, requests do not return the result anymore, but a JobID, which can be used to retrieve the result when it is ready.
Cherry on the cake
Combining message-passing patterns with exponential backoff will take you a long way in your journey to minimize the effect of failures on your availability and are in the top 10 of most important things I have learned to architect for.
Get the skills you need for a better career.
Master modern tech skills, get certified, and level up your career. Whether you’re starting out or a seasoned pro, you can learn by doing and advance your career in cloud with ACG.
That’s it for this installment — I hope you have enjoyed it! Be sure to check out the next part of this series! Please do not hesitate to give feedback, share your own opinion, or simply clap your hands.
-Adrian
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
