SQL on MapReduce with Hive
Hive is a simple yet powerful Hadoop tool that helps provide invaluable insights on petabytes of data using SQL aggregations, joins, and windowing functions.
Oct 5, 2020 • 5 Minute Read
Introduction
Hive is the most popular and the most prevalent member of the Hadoop ecosystem today.
With the increasing popularity of big data applications, MapReduce has become the standard for performing batch processing on commodity hardware. However, MapReduce code can be quite challenging to write for developers, let alone data scientists and administrators.
Hive is a data warehousing framework that runs on top of Hadoop and provides an SQL abstraction for MapReduce apps. Data analysts and business intelligence officers need not learn another complex programming language for writing MapReduce apps. Hive will automatically interpret any SQL query into a series of MapReduce jobs.
Hive Architecture
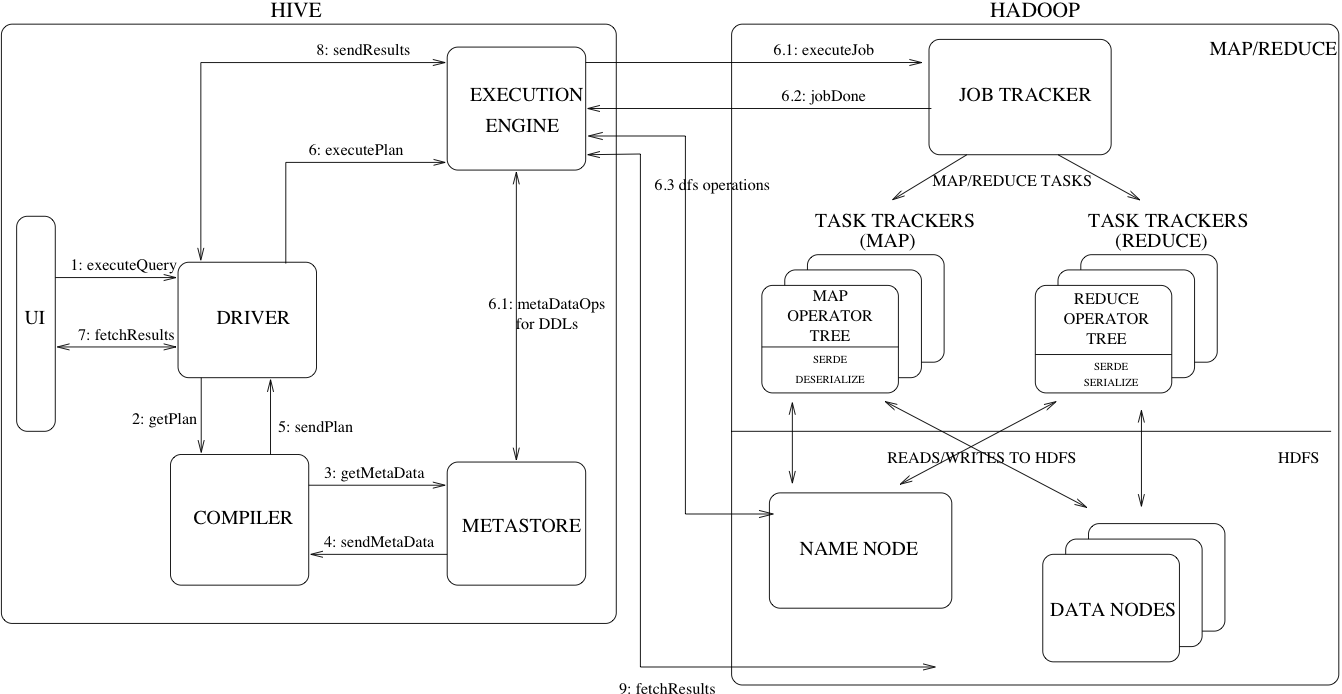
The diagram above showcases the important components of the Hive architecture. An SQL query gets converted into a MapReduce app by going through the following process:
- The Hive client or UI submits a query to the driver.
- The driver then submits the query to the Hive compiler, which generates a query plan and converts the SQL into MapReduce tasks.
- The compiler communicates with the Hive metastore which contains the schema for the data. Any DDL tasks are also performed by connecting to the metastore.
- The execution engine then submits the job to Hadoop for processing.
- Hadoop uses a Hive SerDe, or serializer/deserializer, to covert the input format to and from Hive row objects.
- Finally, the results are retrieved by the UI.
Running a Hive Job
Running a Hive query requires some SQL experience as HiveQL queries are almost indistinguishable from SQL queries.
To connect to a Hive session, run the following command:
beeline -u jdbc:hive2://<ip>:10000/ -n <username>
The default Hive CLI client is called beeline. It connects to a JDBC URL using a specific user that uses the users defined in HDFS and in the operating system to manage permissions.
From the beeline session, you can then run SQL scripts that connect to HDFS locations, or any other location supported by Hive. The following code block is an example of a DDL statement taken from the Amazon Customer Reviews Open Dataset, which connects to Amazon S3.
CREATE EXTERNAL TABLE amazon_reviews_parquet(
marketplace string,
customer_id string,
review_id string,
product_id string,
product_parent string,
product_title string,
star_rating int,
helpful_votes int,
total_votes int,
vine string,
verified_purchase string,
review_headline string,
review_body string,
review_date bigint,
year int)
PARTITIONED BY (product_category string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amazon-reviews-pds/parquet/'
The EXTERNAL TABLE keyword specifies that the table will not be managed by the built-in HDFS hive user. An external table is necessary when storing data outside of the cluster Hive is running on, or even on a directory not owned by the hive user.
Although there is a schema definition written, writes to the location will not be checked by Hive. This is because Hive follows the schema on read principle. The schema is applied as Hive reads the data from the source, and not while data is being inserted. This allows for the reading of more complex file types such as the Parquet file type used in this example. Hive can also be used to read CSV files through the CSV SerDe, complex text files through the RegEx SerDe, and even binary files through custom SerDes and InputFormats.
Conclusion
Simple SQL aggregations, joins, and windowing functions can give invaluable insights when run in a larger scale. Hive is one of many members of the Hadoop ecosystem. It is a very simple yet powerful tool to run analytics on petabytes of data using a familiar language. Since Hive is one of the most commonly deployed members of the Hadoop ecosystem, it is essential for data engineers and data analysts to understand these basic concepts.
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
