Web Scraping with Python
In this python web scraping tutorial, you'll get a step-by-step guide on how to build a web scraper in Python. Automate your scraping with this guide today!
Jan 10, 2019 • 8 Minute Read
Introduction

Let's Begin
Sometimes we will find ourselves needing information (data) from a website. If the website does't contain an API or maybe we just want to check for changing information such as Prices on a ecommerce page or maybe you want to track the up's and downs of bitcoin without constently checking the website. Well, we can write a program for that.
The Flow Is Pretty Simple:
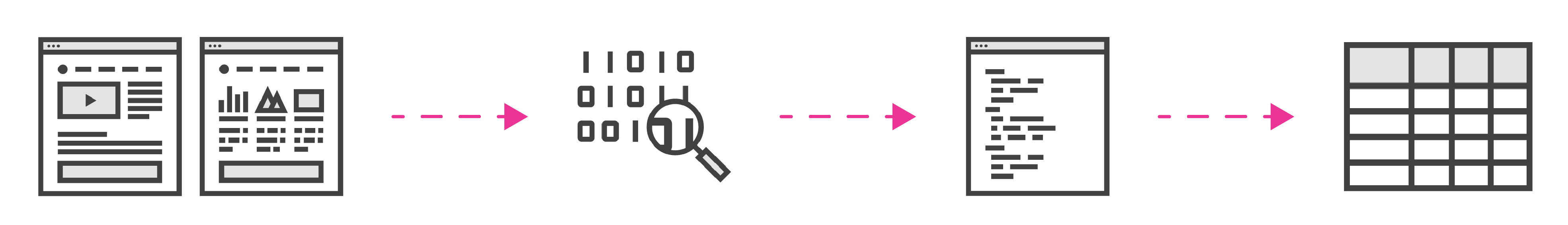
- Search a Webpage
- Inspect it
- Pythonic Magic
- Store your Results.
A quick disclaimer - You'll need to know some the basic anatomy of HTML.
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<h1> Why Web Scraping </h1>
<p> Scrape All The Things!! </p>
<body>
</html>
Essentially, you're loading a webpage and peaking behind the curtain. We will write a script that grabs the HTML and then parses it into usable chunks.
The basic framework (behind the curtain) of a webpage is HTML & CSS. Just think of HTML as a structure and CSS as the structure's style. The layout of a webpage is super important as you will come to find later. HTML is great because it's predictable and structured.
Toolbox
We will be using the following:
- Python 3.6
- Terminal
- IDLE 3.6 (comes with Python)
For this example we will be using the following Python Packages:
If you do not have Python, do not fear. Simply open the Python link above, download it, and install it (3.x and above). If you have Python and are unsure of what version you are using. Open Terminal and type python and click enter.
$ Python
You'll see the version populate like below.
Python 3.6.3 (v3.6.3:2c5fed86e0, Oct 3 2017, 00:32:08)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
When you're finished type exit() to quit Python but remain in the terminal.
$ exit()
Now let's install our packages. While in terminal type the following: pip install. If you get errors, or it's installing to Python 2, please use pip3 install instead.
$ pip install beautifulsoup4
and
$ pip install requests
To make sure everything is working you can now simply type python - or - if you have multiple versions of python type in python3 to run Python 3.x.
$ Python
Next import your packages: BeautifulSoup and Requests.
import bs4, requests
It should look something like this.

>>> Is a good sign!!! If there was an error you would get a bunch of nasty literature...
Now that we have Python and our packages are imported let's scrape. To do this I will be using IDLE, feel free to use what ever text editor you like.
Let's Make a Program
Again you can use Terminal for this whole process, but I would encourage you to use a text editor so you can easily save your .py program which can later be opened by Terminal. Secondly, if you'd like, you can complete this in the terminal line by line which is great for testing. Meaning, you cannot move forward until your errors are resolved. Sometimes it's easier to use Terminal until you know everything is working properly, then simply copy it to your .py program. The choice is yours.
Type in the following.
import requests
from bs4 import BeautifulSoup
When importing, remember packages are case sensitive. If you type beautifulsoup you'll get an error, so make sure you type your packages correctly.
Let's grab a website. For this example we will use something simple.
Here is the URL: Cow Mask
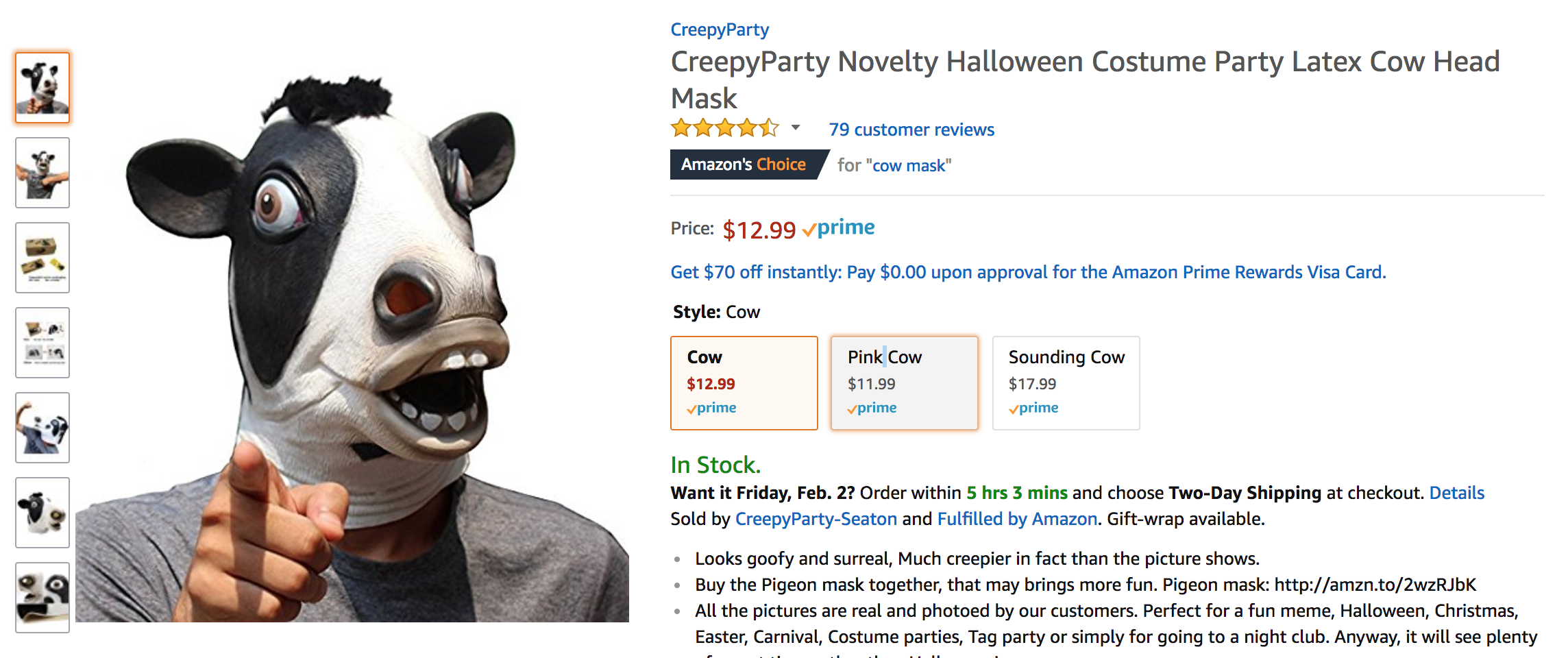
Let's say this product is too expensive and we want to keep checking to see if it will come down.
First, we need Python to connect to the URL and then grab the HTML.
Type the following:
source = request.get("https://www.amazon.com/CreepyParty-Novelty-Halloween-Costume-Party/dp/B0199PV50K/ref=pd_sim_21_3?_encoding=UTF8&pd_rd_i=B0199PV50K&pd_rd_r=9CN0FB2X3B4YRY4JBSHW&pd_rd_w=yoPuL&pd_rd_wg=AsYde&psc=1&refRID=9CN0FB2X3B4YRY4JBSHW").text
We just grabbed our URL with requests and stored it into a variable called "source". To simplify, we took information and placed it into a box called "source" That way when we need it, we don't need to type "request.get('https://www.......')" over and over, we simply need to type "source". Essentially, to get source code from the responce object we'll use .text
Next type:
soup = BeautifulSoup(source.html, 'lxml')
We are taking the stringed HTML and will be passing it through BeautifulSoup to be parsed. Now, lets print out the code to be examined. At it's current state printing it would result in nasty looking code that would be horrible to read. So, to make it readable like the HTML example above will use a function in BeautifulSoup called prettify.
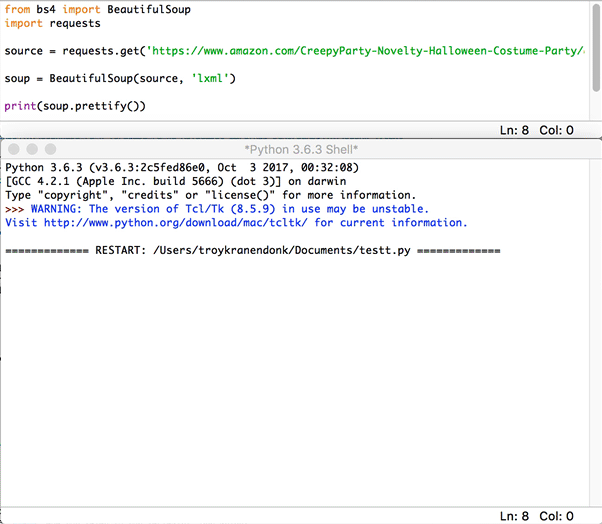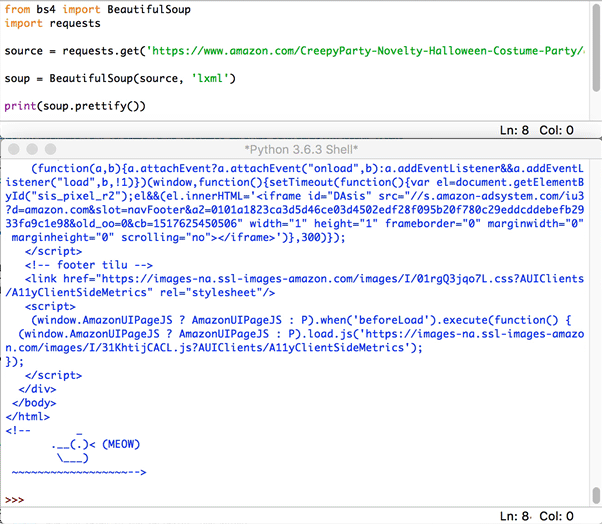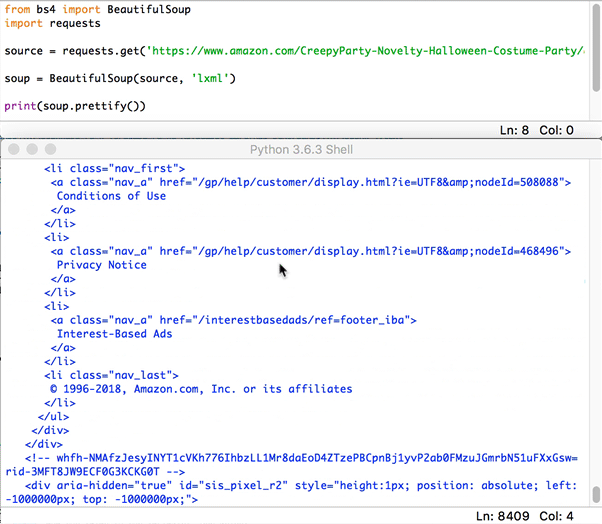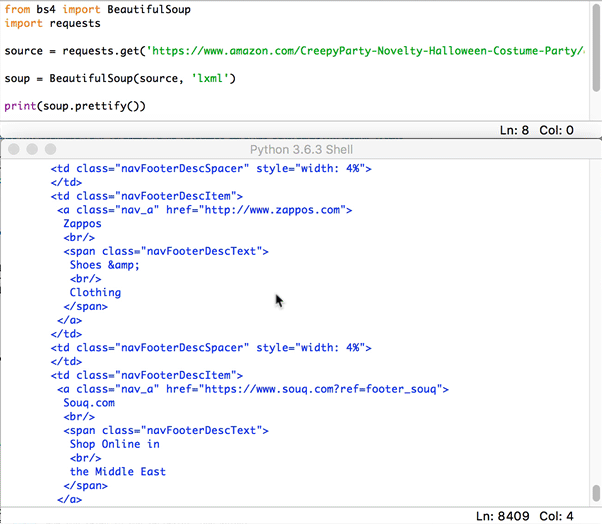
print(soup.prettify())
Click to Reveal the Prettify Example
{kind=link}
Just keep in mind, it will take 2-4 seconds to load, it will display the entire html of that page, so depending on the site it may be chunky.
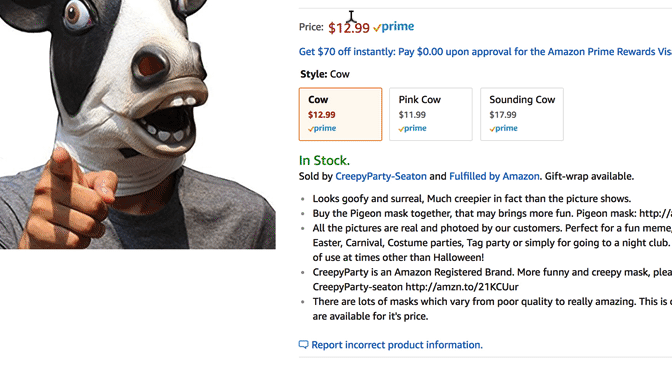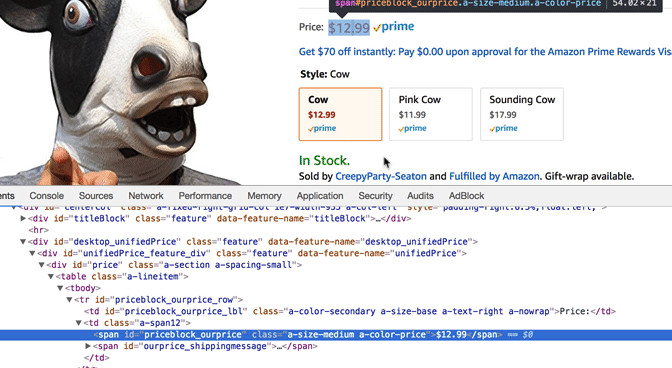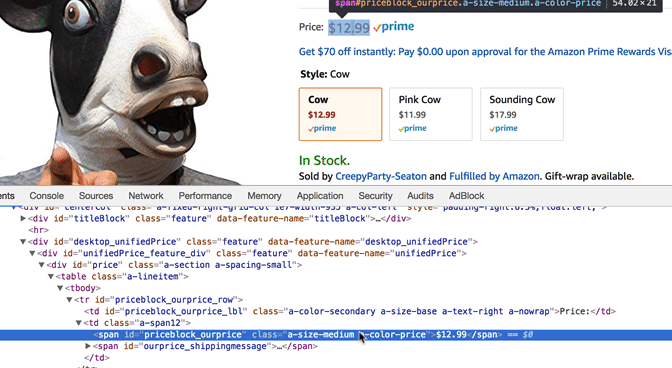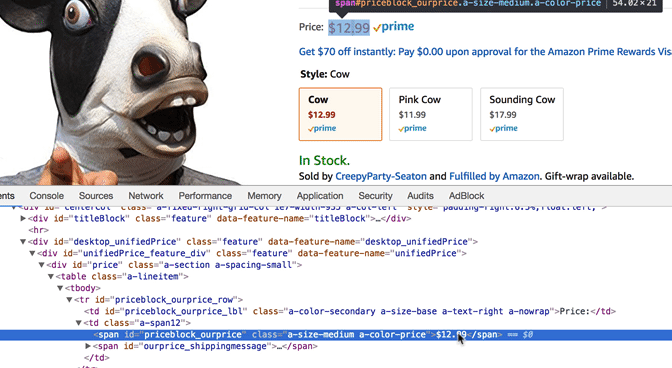
Alright, we can see that our program is correctly taking the HTML and displaying it in a readable format. Now lets find the HTML code the corresponds to the price we want to scrape. In Google Chrome right click on the price "$12.99" and click inspect.
Click To Reveal the Inspect Example
{kind=link}
We can see that the price is found in a Span. The exact code is found below.
<span id="priceblock_ourprice" class="a-size-medium a-color-price">$12.99</span>
Let's look at it closer. The span also has a unique class called "a-size-medium a-color-price". We can use that to find the price with ease.
We are going to create a variable called "price". Next we are going to use a function of soup called "find" in order to locate the <span>. Next, we need to place the class and the value in the variable. See below.
price = soup.find('span', {'class' : 'a-size-medium a-color-price'})
All that's left is to print "price". Don't forget to include "text" other wise it will just print the entire <span class="a-size-medium a-color-price" id="priceblock_ourprice">$12.99</span>.
print(price.text)
Here is the entire script.
from bs4 import BeautifulSoup
import requests
source = requests.get('https://www.amazon.com/CreepyParty-Novelty-Halloween-Costume-Party/dp/B0199PV50K/ref=pd_sim_21_3?_encoding=UTF8&pd_rd_i=B0199PV50K&pd_rd_r=9CN0FB2X3B4YRY4JBSHW&pd_rd_w=yoPuL&pd_rd_wg=AsYde&psc=1&refRID=9CN0FB2X3B4YRY4JBSHW').text
soup = BeautifulSoup(source, 'lxml')
#print(soup.prettify())
price = soup.find('span', {'class' : 'a-size-medium a-color-price'})
print(price.text)
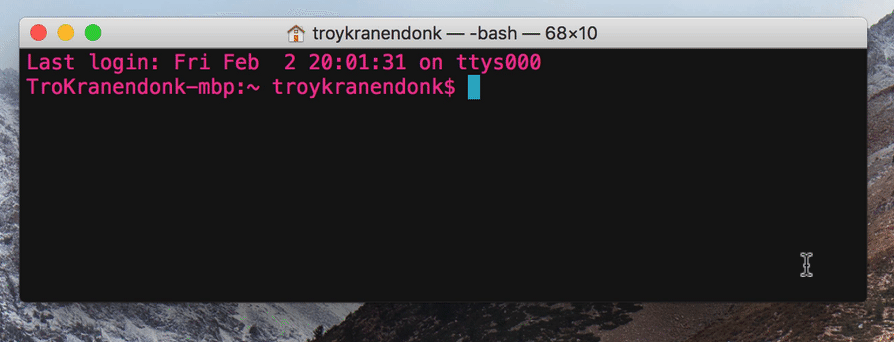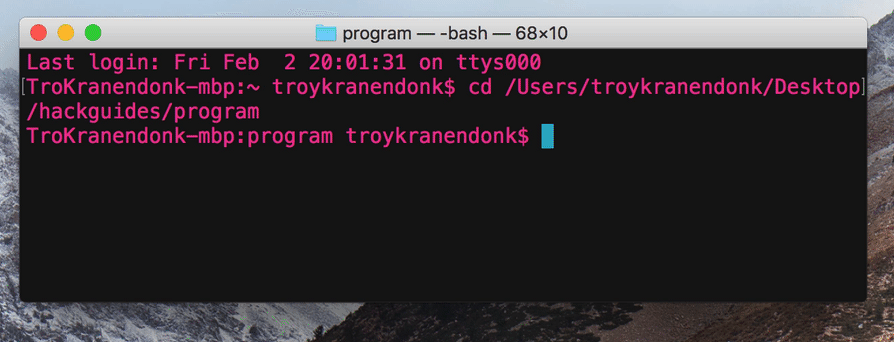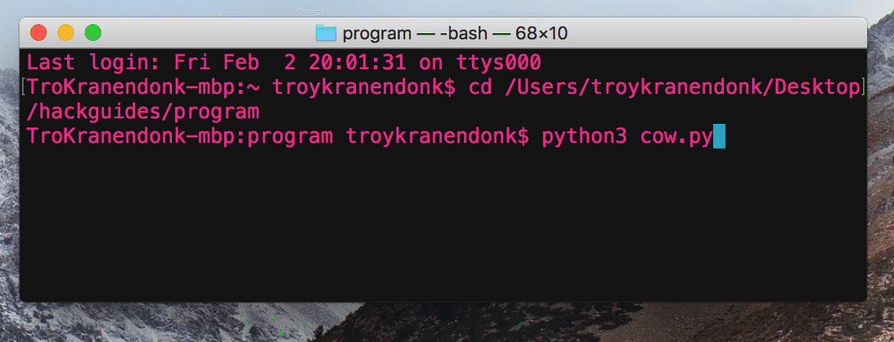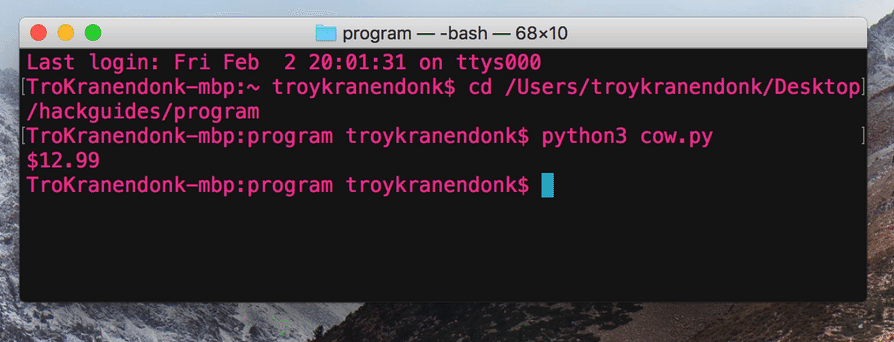
Let's see it in action. I'm just going to open Terminal and run the program that I saved. Let's see it in action.
Click To Reveal the Inspect Example
{kind=link}
Success!!
Yes, it's just a price, however, we could scrape multiple sections or sites to gather data with ease. All that we need to do is simply run our program and we'll get the price and the best part is, we'll never have to open up a browser.
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
