Getting Started with Hadoop MapReduce
Hadoop uses MapReduce to process large quantities of data by breaking big problems into smaller ones, distributing tasks across nodes, and aggregating results.
Sep 24, 2020 • 5 Minute Read
Introduction
Distributed systems have gained popularity for their efficiency in processing big data. Several approaches exist for processing large volumes of data by leveraging a compute cluster. Hadoop uses a divide-and conquer-paradigm. It breaks big problems into smaller ones, distributes the tasks across nodes, and later aggregates individual results to form the final output.
The component that performs processing in Hadoop is MapReduce, a software framework designed to process large data in parallel on a distributed cluster.
MapReduce works by splitting the input data into smaller chunks and feeding them to processing components referred to as mappers. The mappers then pass on their processed output to reducers, which produce the final output.
The guide assumes that you have a basic understanding of the overall Hadoop architecture. An introductory guide to Hadoop can be found here.
MapReduce Architecture and Function
To perform its functions, the architecture contains two main processing elements designed in a controller-operator fashion. These are:
1. Job Tracker: The controller. Responsible for job scheduling and issuing execution commands to the operator component that resides in each node. It is also responsible for re-executing failed tasks.
2. Task Tracker: The operator. Exists on each node and executes instructions and relays feedback back to the controller component.
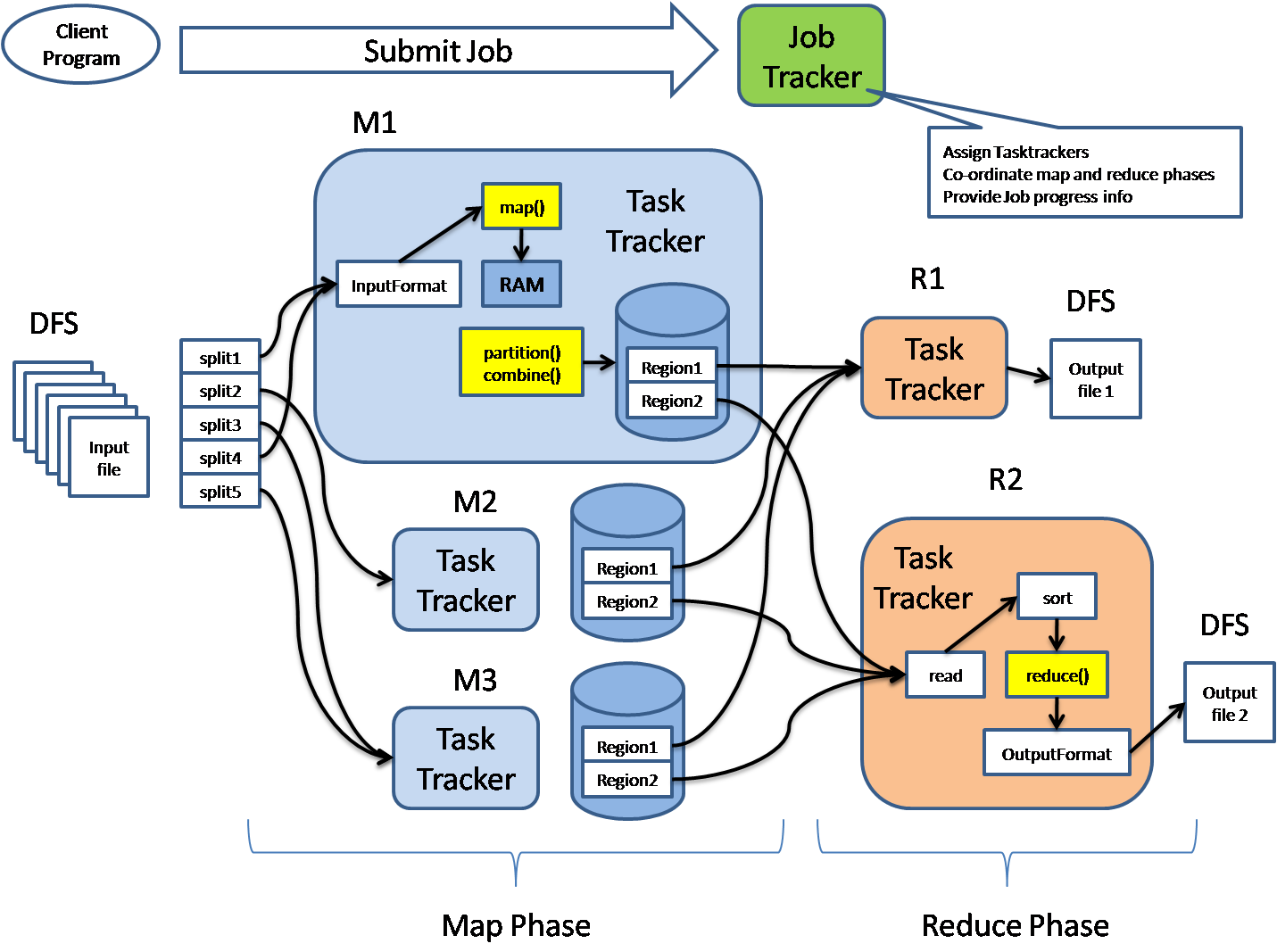
As demonstrated above, the functioning of MapReduce occurs in two phases: the map phase and the reduce phase.
Map Phase
This is the first phase that occurs during the execution of a processing task in the Hadoop system. The framework understands data in the form of <key,value> pairs, and hence, the input data has to be pre-processed to match this expected format. The input dataset is broken down into smaller chunks via a method referred to as logical splitting.
The logical chunks are then assigned to available mappers, which process each input record into <key,value> pairs. The output of this phase is considered intermediate output.
The output can undergo an intermediate process where the mapper output data is further processed before being fed into the reducers. The processes include combining, sorting, partitioning, and shuffling. More about the significance of these processes can be found here. The intermediate data from these processes are stored in a local file system within the respective processing node.
Reduce Phase
The number of reducers for each job is configurable and can be set within the mapred-site.xml configuration file.
The reducer phase of processing takes the mapper phase output and processes the data to generate the final output, which is recorded in an output file within the Hadoop Distributed File System (HDFS) by a function referred to as record writer.
Practical Example
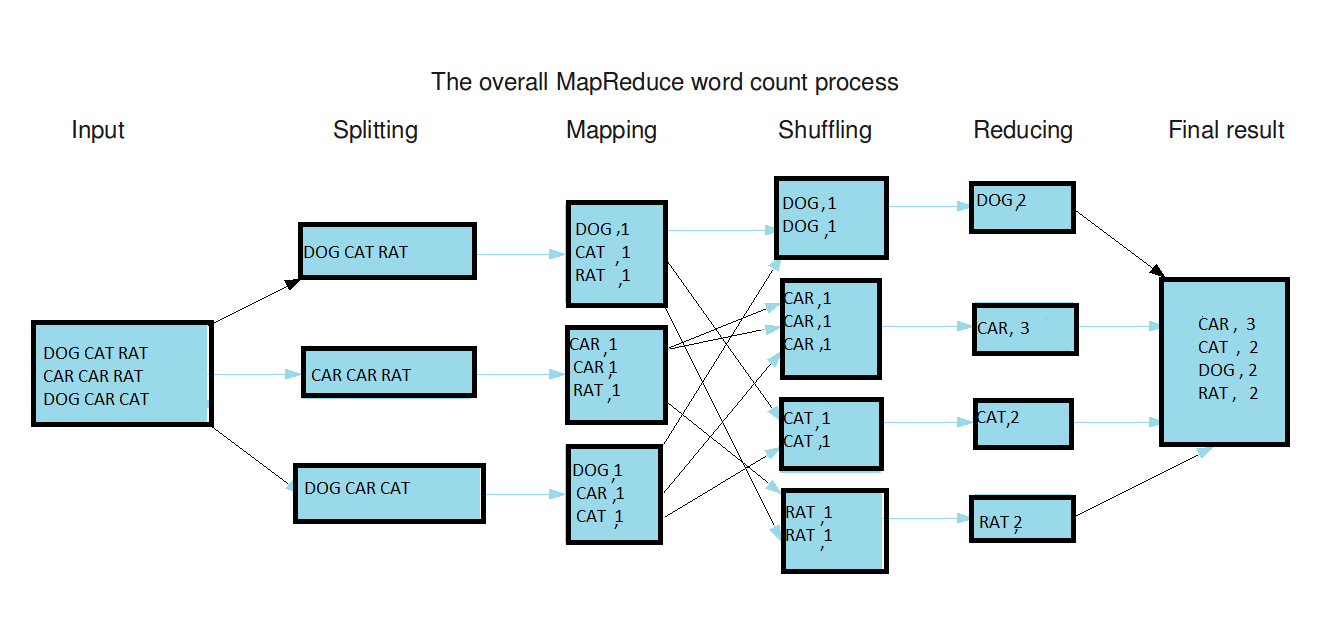
Conclusion
You have now gained knowledge of the MapReduce programming paradigm and how it is implemented in distributed computing to facilitating distributed parallel processing of large datasets. The main approach is to divide and conquer. This skill is vital for any developer holding the role of big data engineer or distributed compute architect in their organization.
To further build on this guide, study more about distributed and parallel computing, especially how resources are negotiated and allocated in a distributed cluster to handle processing and storage. In Hadoop, resource negotiation and allocation are performed by YARN. An introductory guide to Hadoop's YARN can be found here.
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
