R and Python Scripts in Azure ML Studio
Sep 15, 2020 • 9 Minute Read
Introduction
One of the important capabilities of Azure Machine Learning Studio is that it is possible to write R or Python scripts using the modules provided in the Azure workspace. This enables data scientists leverage their knowledge of R and Python within the workspace. In this guide, you will learn how to use these modules to run R and Python codes in Azure Machine Learning Studio.
Data
In this guide, you will work with fictitious data of 600 observations and four variables, as described below.
-
Dependents: Number of dependents of the applicant.
-
Credit_score: Whether the applicant's credit score was good ("1") or not ("0").
-
Age: The applicant’s age in years.
-
approval_status: Whether the loan application was approved ("1") or not ("0"). This is the dependent variable.
Start by loading the data.
Loading Data
Once you have logged into your Azure Machine Learning Studio account, click on the EXPERIMENTS option, listed on the left sidebar, followed by the NEW button. Next, click on the blank experiment and the new workspace will be displayed. Give the name Execute Scripts to the workspace.
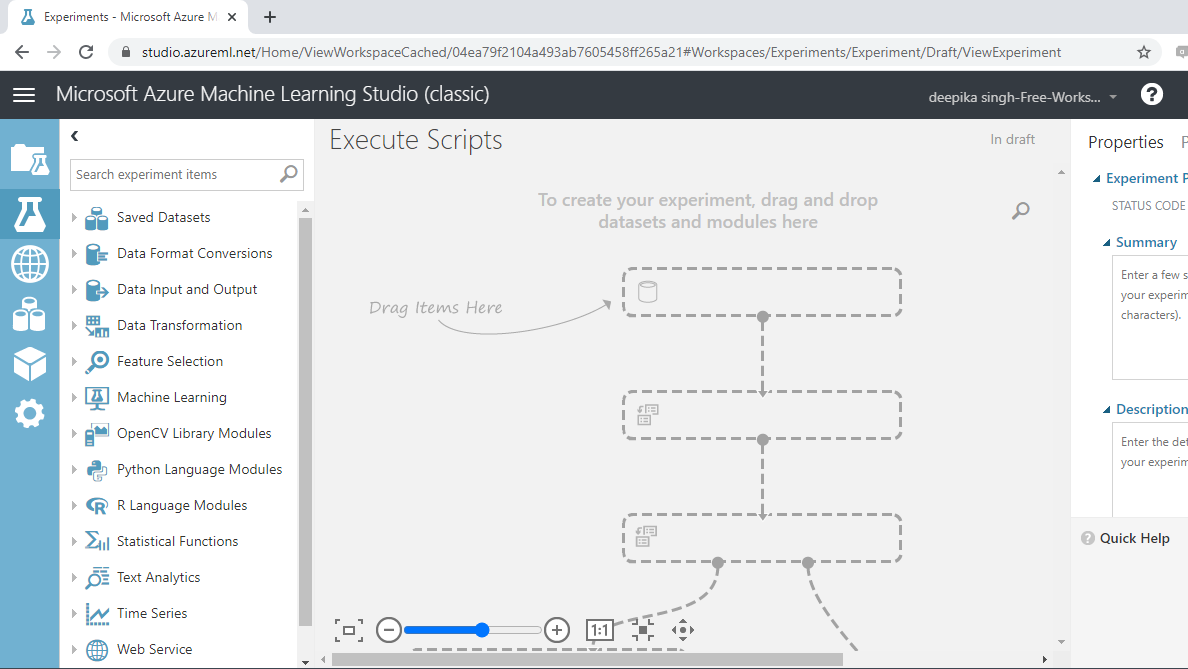
Next you will load the data into the workspace. Click NEW, and select the DATASET option.
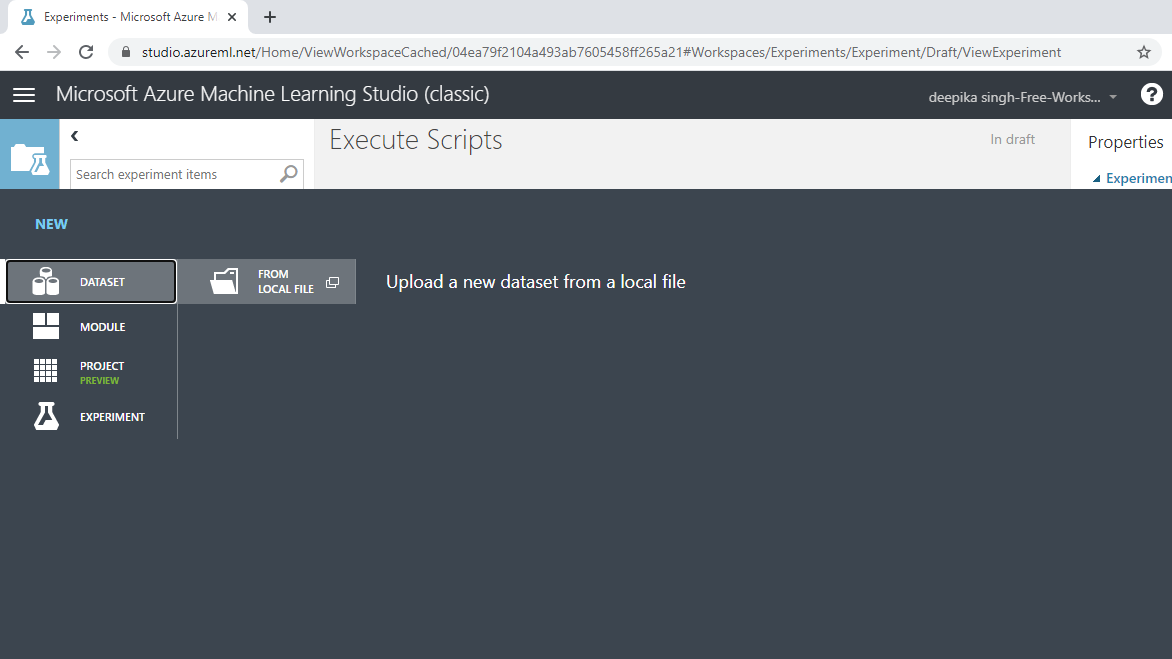
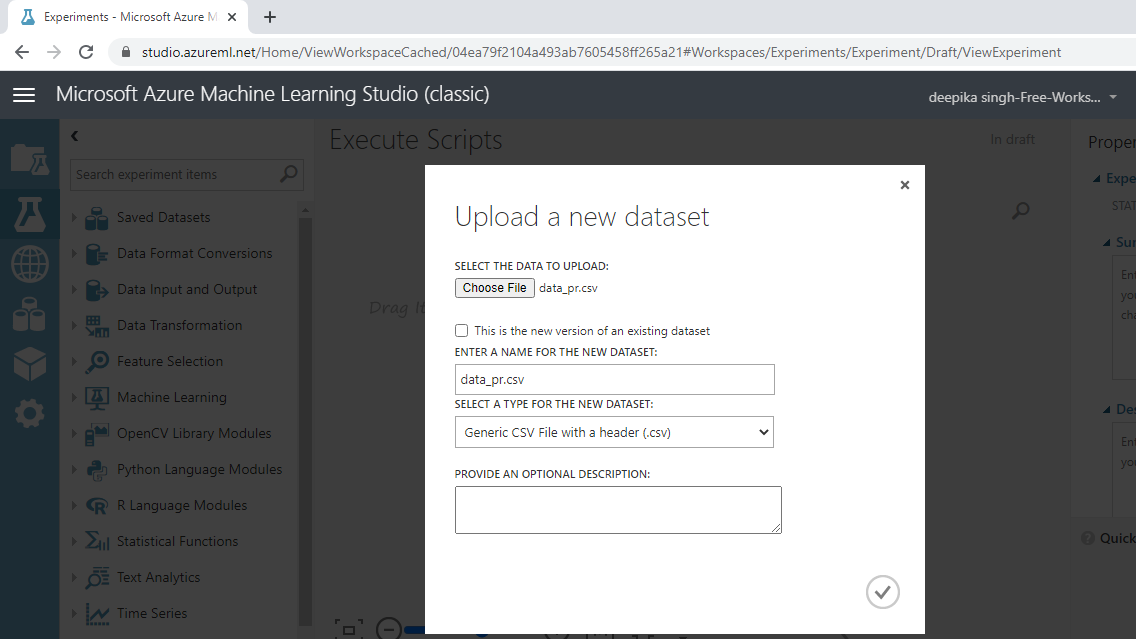
The selection above will open a window shown below, which can be used to upload the dataset from the local system.
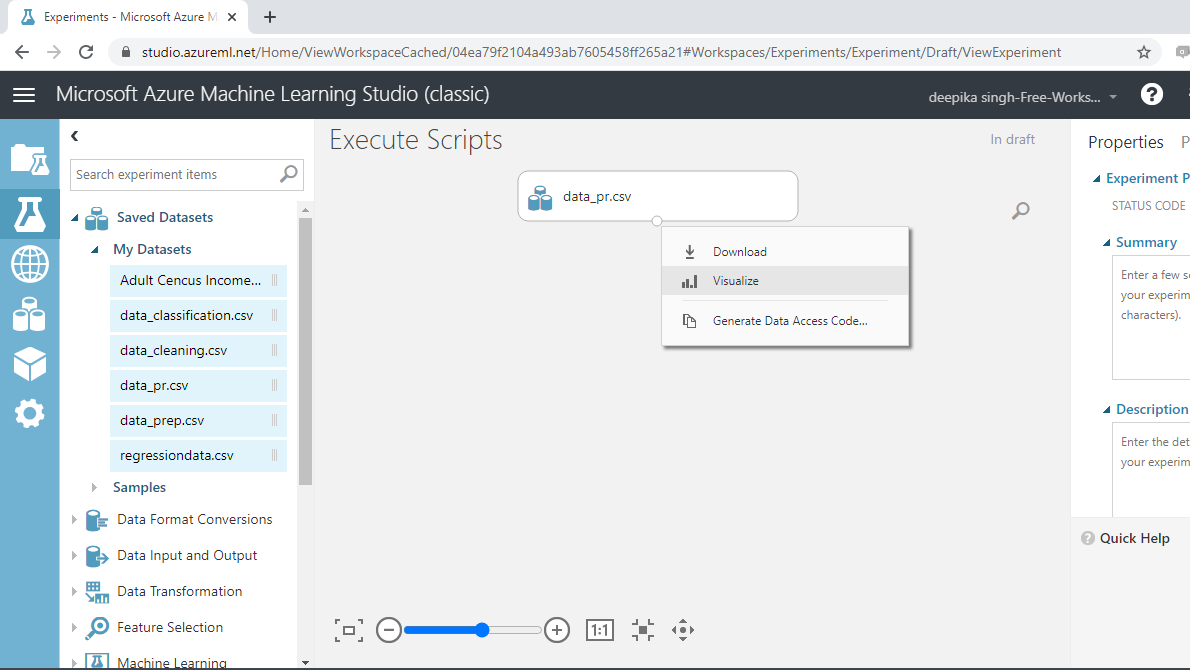
Once the data is loaded, you can see it in the Saved Datasets option. The file name is data_pr.csv.
Exploring the Data
To begin, drag the data from the Saved Datasets list into the workspace. Next, right-click and select the Visualize option as shown below.
Select the different variables to examine the basic statistics. For example, the image below displays the details for the variable Age.
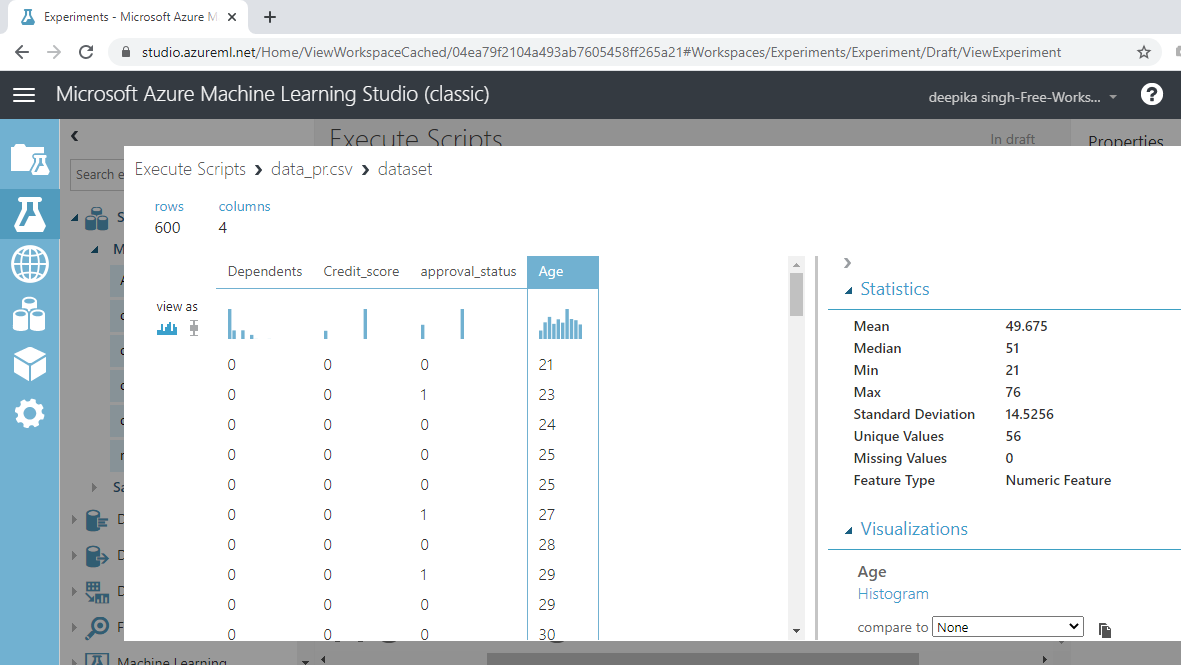
You will notice the summary statistic of the variable. Next, look at the variables approval_status.
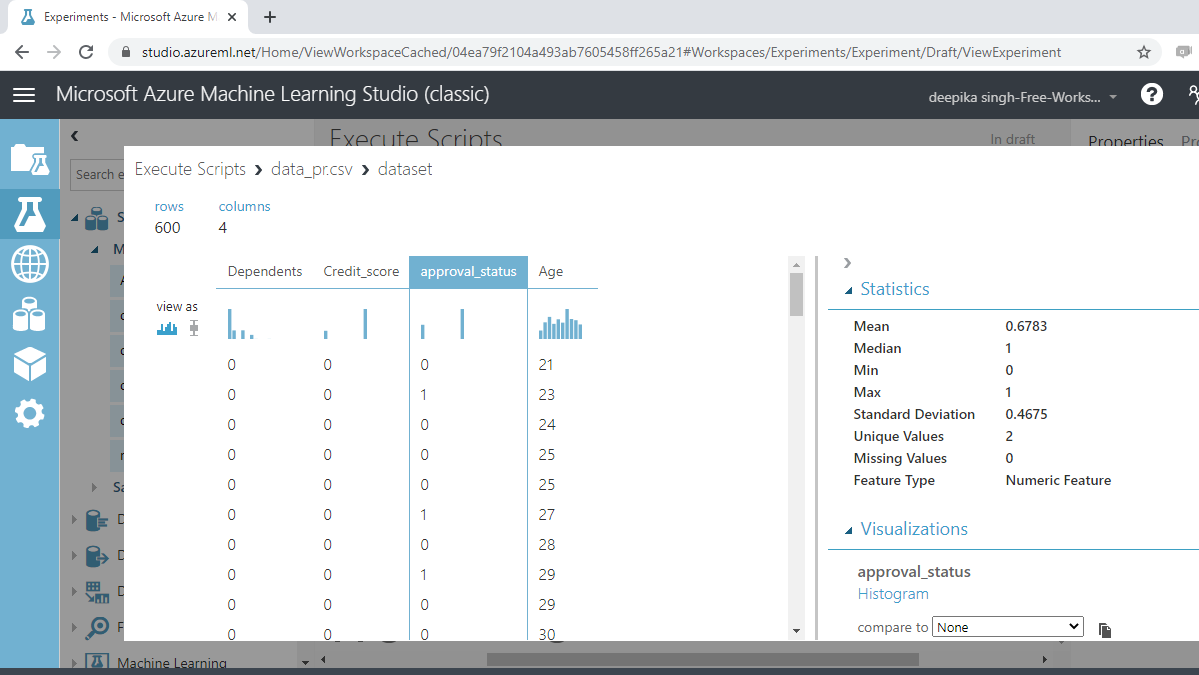
This is a categorical variable that is represented as numeric. You will be changing the data type with the Execute R Script module.
Execute R Scripts
The Execute R Script module can be used to execute R codes in the machine learning experiment. You can perform tasks such as data preparation, data exploration, and machine learning with the R code. You will convert the data types of variables, Dependents, Credit_score, and approval_status, with the R script.
To begin, search and add the Execute R Script module to your experiment. Next, connect the data to the first input port (left-most) of the Execute R Script module. Click on the module and under the ** Properties** pane. You will see the option of writing your R script. Enter the code as shown below.
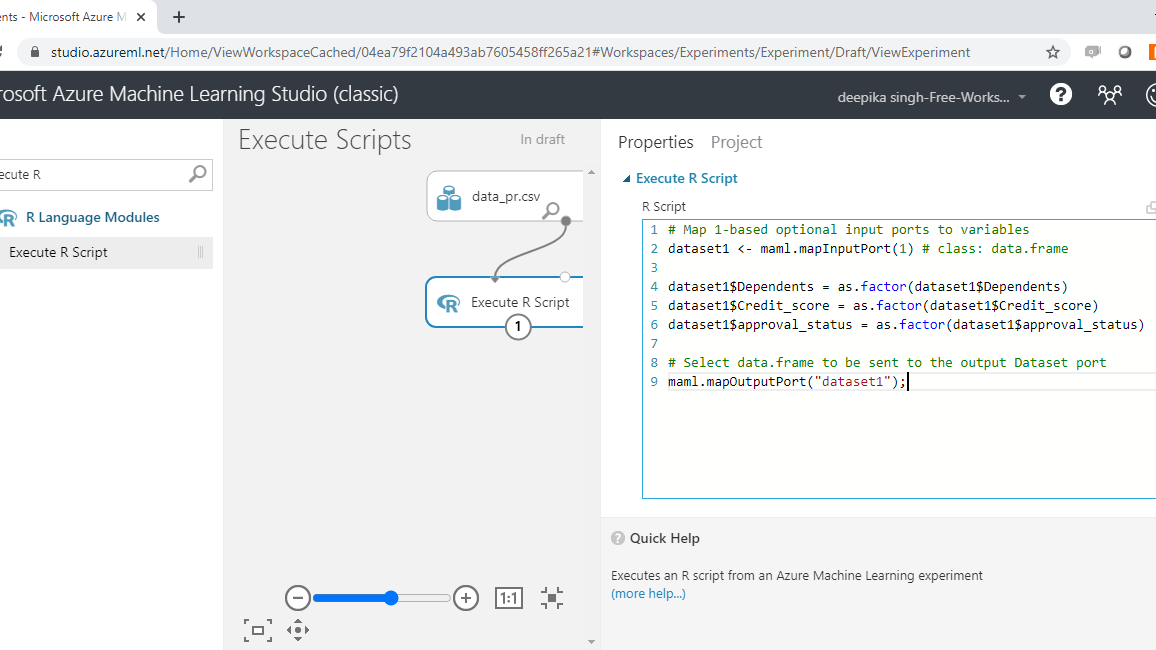
You can also copy the code from below.
dataset1 <- mam1.mapInputPort(1)
dataset1$Dependents = as.factor(dataset1$Dependents)
dataset1$Credit_score = as.factor(dataset1$Credit_score)
dataset1$approval_status = as.factor(dataset1$approval_status)
mam1.mapOutputPort("dataset1");
In the code above, the first line creates a dataframe, dataset1, which is mapped to the first input port with the function, mam1.mapInputPort(). The second through fourth lines of code use the as.factor() function to convert the numeric variables to categoric. Finally, the mam1.mapOutputPort(“dataset1”) function saves the resulting output in the first left-most output port of the Execute R Script module.
You can set the random seed to 11, and keep the other options to default.
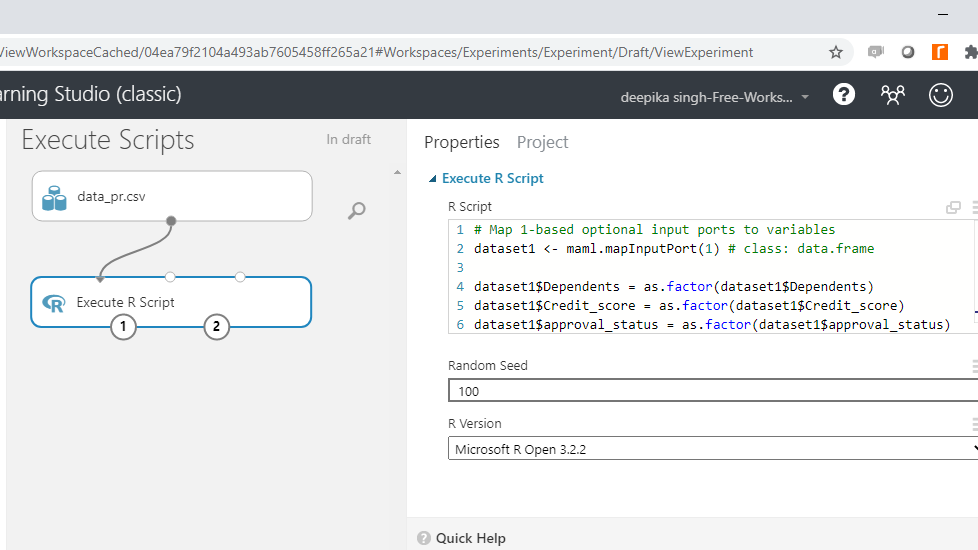
Run the experiment. On successful completion, you can see the green tick in the module.
Right click and select Visualize to look at the data again.
If you click on the approval_status variable, you will see that the feature type is now categorical.
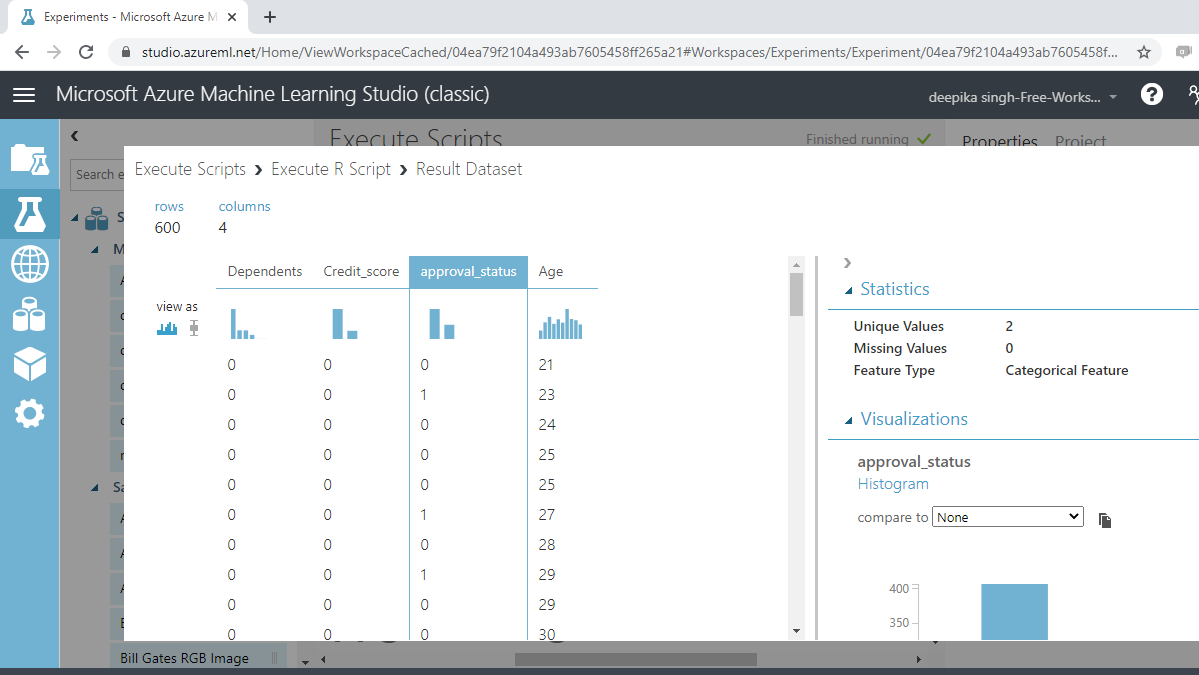
You have converted the variables Dependents, Credit_score, and approval_status to categoric with the R scripts.
Execute Python Scripts
The Execute Python Script module can be used to call and run Python codes in the Azure Machine Learning Studio experiment.
You have converted the variables to categoric using the Execute R Script module. The only numeric variable is Age. While building machine learning models, there are times when you might want to convert the numeric feature to categoric by a process called binning. One such algorithm is the Naïve Bayes algorithm that requires all the features to be categorical.
You will perform binning on the Age variable with the Python script. To begin, search and add the Execute Python Script module to your experiment.
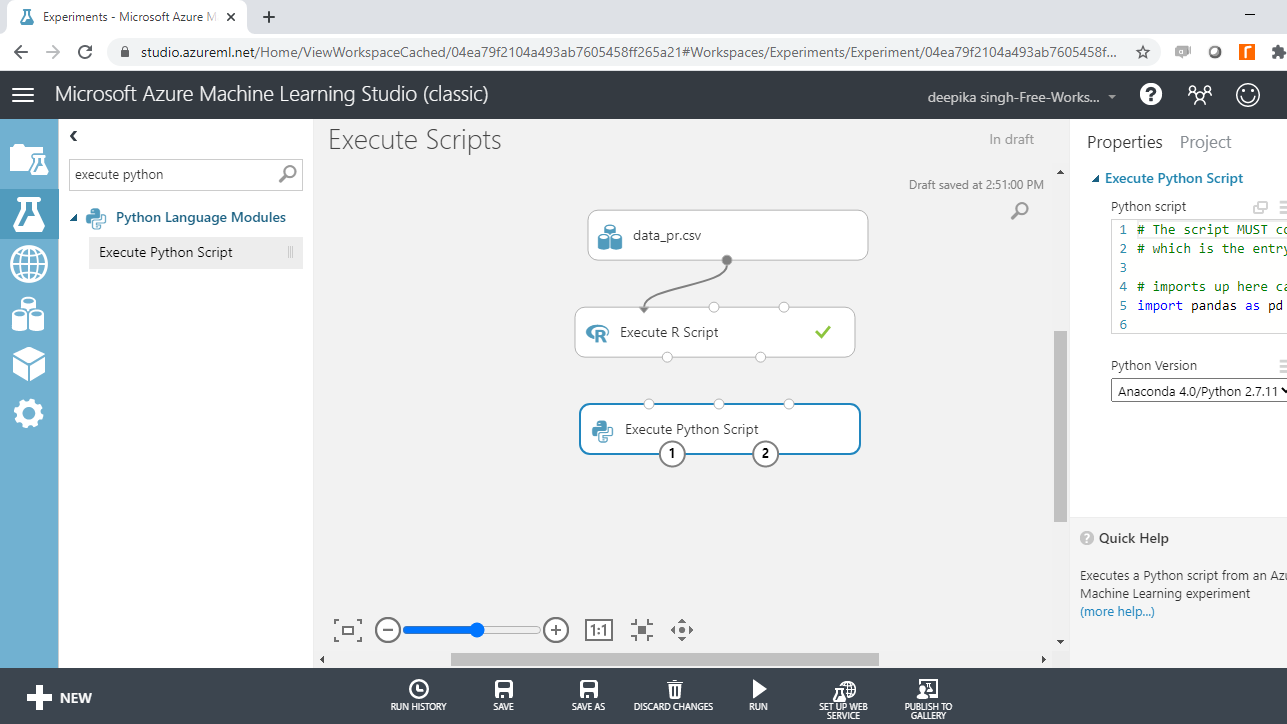
Next, connect the data to the first input port (left-most) of the Execute Python Script module, as shown below.
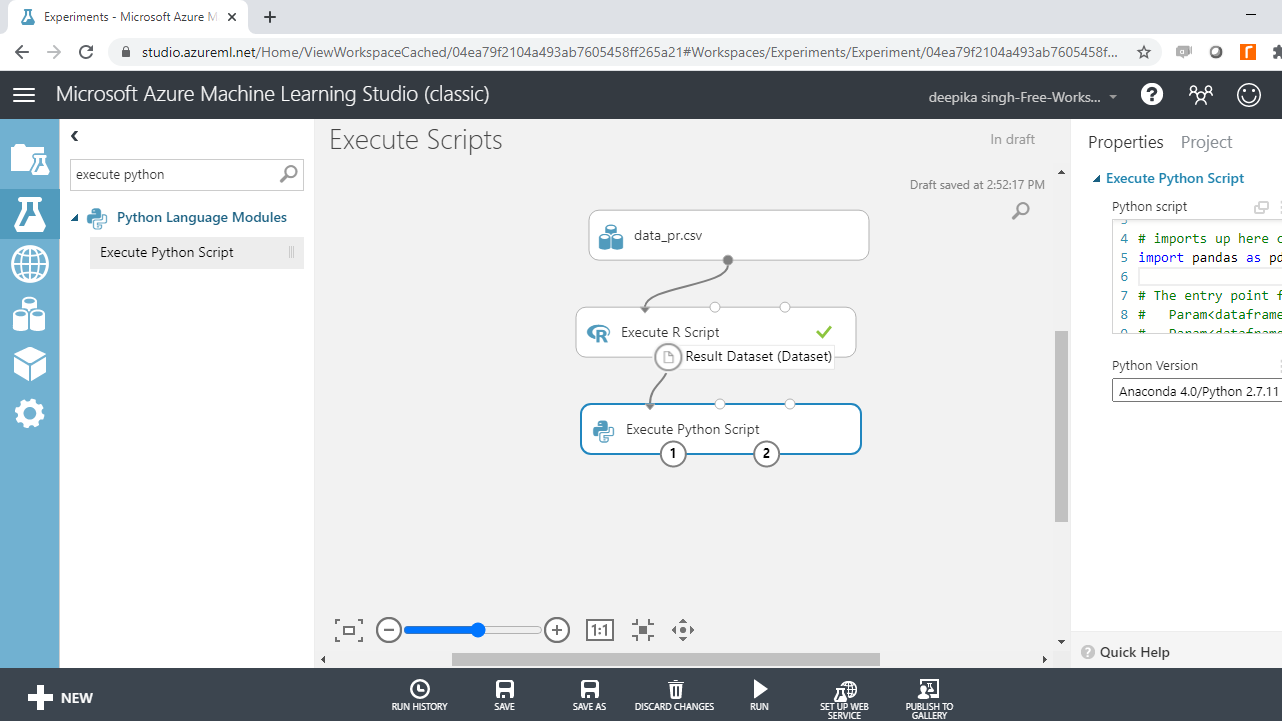
Click on the module and under the Properties pane, you will see the option of writing your script. Enter the code as shown below.
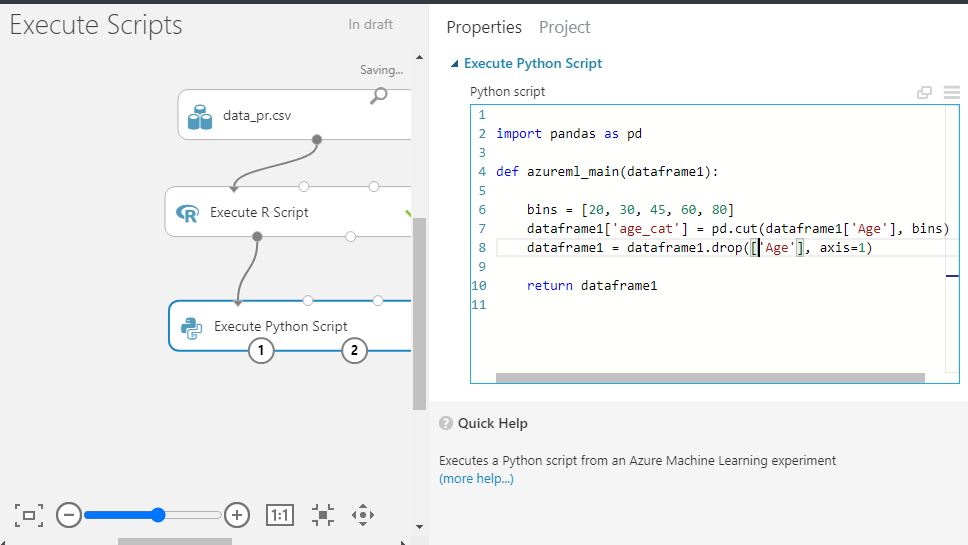
You can also copy the code from below.
import pandas as pd
def azureml_main(dataframe1):
bins = [20,30,45,60,80]
dataframe1['age_cat'] = pd.cut(dataframe1['Age'],bins)
dataframe1 = dataframe1.drop(['Age'],axis=1)
return dataframe1
The first line of this code imports the pandas library. The second line follows the mandatory convention of including the function, named azureml_main(), as the entry point for this module.
The second line creates the function and the third line creates the bin ranges. The fourth line uses the pd.cut function to create the age_cat variable. The fifth line drops the Age variable from the dataset. Finally, the sixth line returns the resulting dataframe.
Click on Run and select the Run selected option.
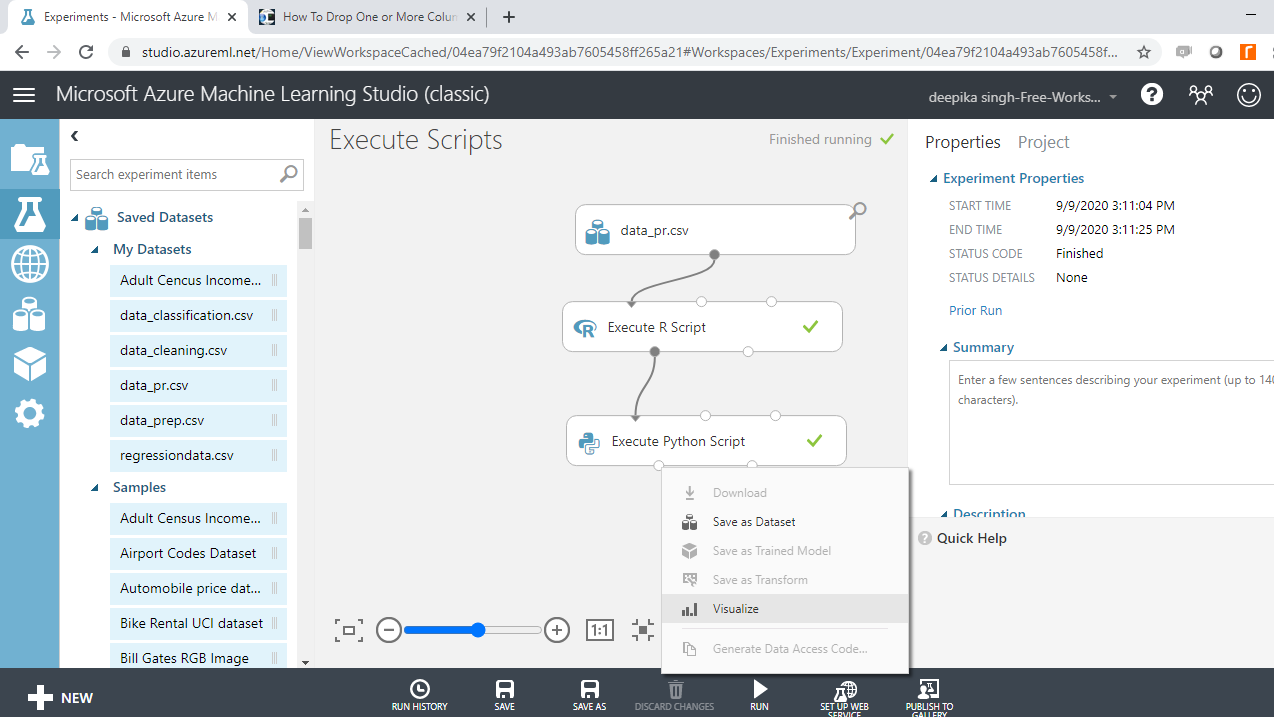
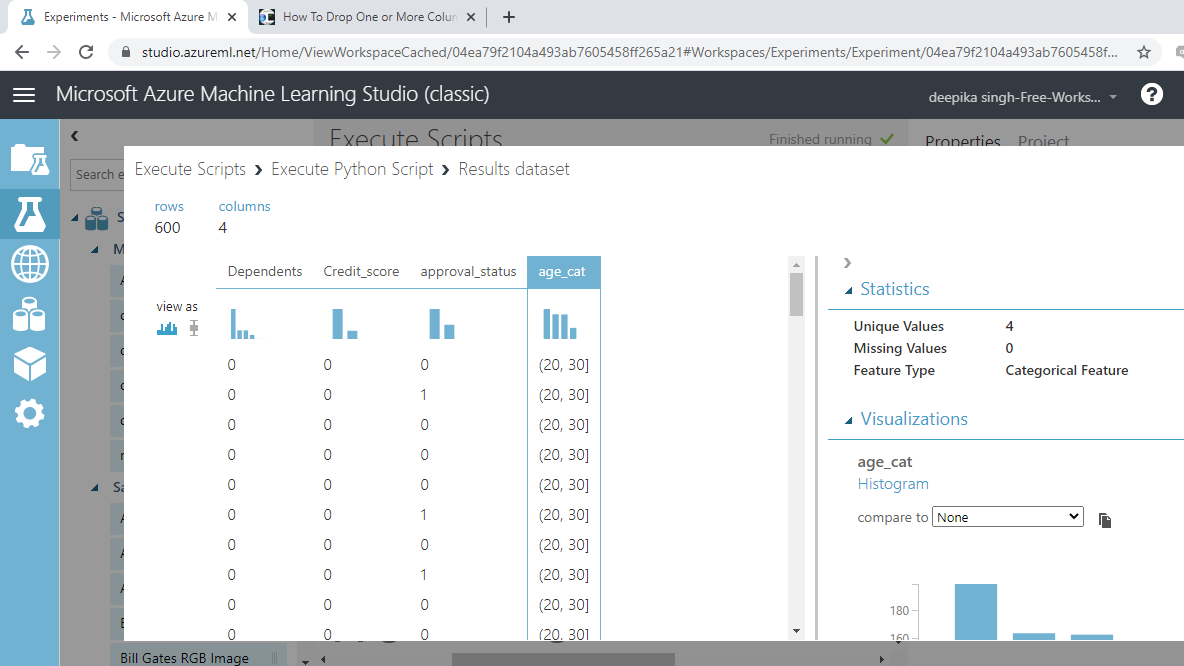
Once the module run is completed, right click and select Visualize.
You will note that the variable Age has been removed and a new categorical feature, age_cat, is created. This has four unique categories and can now be used as categorical variable.
Conclusion
In this guide, you learned how to call and run R or Python scripts using the modules provided in the Azure workspace. This will help you integrate Azure Machine Learning Studio capabilities with your R and Python programming skills.
To learn more about data science and machine learning using Azure Machine Learning Studio, please refer to the following guides:
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
