Transactional Processing with HBase
HBase (Hadoop Database) is an open source project that attempts to give Hadoop the ability to make fast, transactional writes to its filesystem.
Oct 7, 2020 • 7 Minute Read
Introduction
Hadoop and the members of the Hadoop ecosystem have been known as primarily tools for big data analytics and durable storage. Although they can analyze Terrabytes and even Petabytes of data efficiently, the original Hadoop applications were not meant to efficiently handle transactions, particularly writes to HDFS.
HBase (Hadoop Database) is an open source project that attempts to give Hadoop the ability to make fast, transactional writes to its filesystem. It takes advantage of Hadoop's distributed computing environment to build a durable, consistent, yet high-performing database.
HBase Schema
HBase is a wide column key-value store adapted from Google's Big Table. Each row has a specific key known as a rowkey. The data in your HBase cluster is stored lexicographically by that rowkey. The data in the row are represented by columns, which are grouped together into column families. Columns within a column family are stored physically close to each other to take advantage of data locality and minimize communication across nodes.
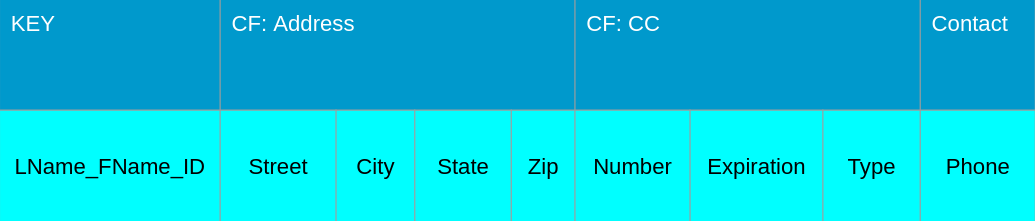
The key in this case is a concatenation of last name, first name, and customer identification number (e.g., armstrong_alice_8570365786). There are three column families: address, cc, and contact. This means that all of a specific customer's address information is stored together on the same physical machine. Their credit card information, since it all belongs to one column family, is also stored together on the same machine, though it may not be on the same machine as the other column families.
Assuming you have Hadoop and HBase installed in your cluster, you can create a table by first running an HBase shell:
hbase shell
Then run the create command. The general syntax of the create command is:
create '<table_name>', '<column_family_1>', '<column_family_2>', '<column_family_3>', . . . '<column_family_n>'
To create the table illustrated by the schema above, run the following command:
create 'customer', 'address', 'cc', 'contact'
HBase Architecture
Overview
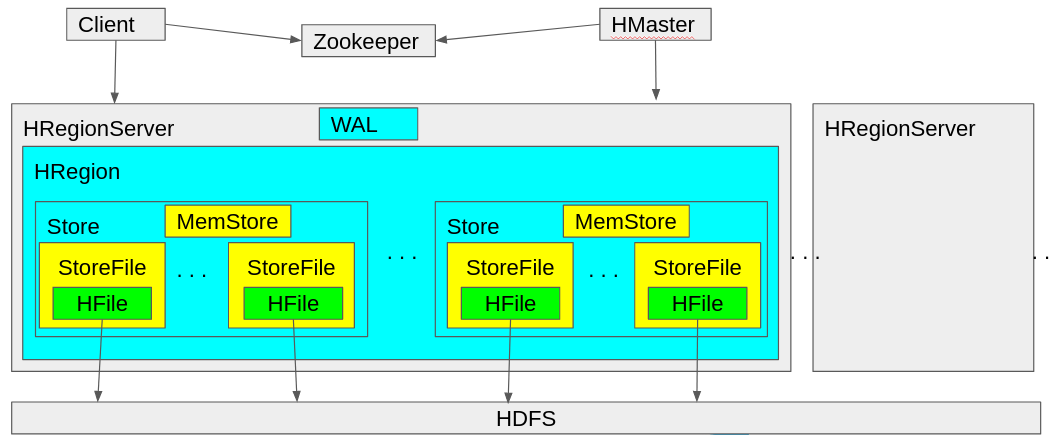
HBase consist of several services that coordinate with each other through Zookeeper, a distributed service discovery and configuration management server. A certain range of rows is stored in HRegions and served by an HRegionServer. An HRegionServer may serve one or many HRegions. The HMaster determines what HRegion each row is stored in, assigns the store each column family is stored in, and updates the state of the cluster on Zookeeper.
The HBase client communicates with the HMaster for DDL statements, but mostly interfaces with the HRegionServer directly to query table data. The client relies on Zookeeper to identify what rows are stored in a particualr region.
Stores
Each store on HBase consists of a MemStore and zero or more StoreFiles. The MemStore stores all recent writes to HBase in memory for faster data retreival. When the MemStore reaches the limit specified in the hbase.hregion.memstore.flush.size configuration property, the data in the MemStore is flushed to HDFS in the form of StoreFiles. A StoreFile contains an HFile where the HBase data actually resides. Technically speaking, HFiles and StoreFiles are separate entities, but they are used interchangeably in practice.
High availability may be an issue if data is not flushed to HDFS. If there is some sort of cluster failure, all data stored in memory, and therefore all the data in the MemStore, is erased. To recover from such failures, HBase maintains a Write Ahead Log, or WAL, to store all recent changes made to the table on HDFS. This allows HBase to replay these changes should there be any node failure in the cluster.
Inserting Data into HBase
Now that you understand the basic schema and architecture of HBase, you can begin inserting data into HBase. The general syntax for data inserts using the HBase shell is as follows:
put '<table_name>','<rowkey>','<column_family>:<column>','<value>'
You can insert only one value in one column per put command. The following code block inserts information for two customers in your customer table.
put 'customer','armstrong_alice_8570365786','address:city','Claraport'
put 'customer','armstrong_alice_8570365786','address:state','NH'
put 'customer','armstrong_alice_8570365786','address:street','Melany Gateway'
put 'customer','armstrong_alice_8570365786','address:zip','53522'
put 'customer','armstrong_alice_8570365786','cc:number','1212-1221-1121-1234'
put 'customer','armstrong_alice_8570365786','cc:expire','2024-04-12'
put 'customer','armstrong_alice_8570365786','cc:type','visa'
put 'customer','armstrong_alice_8570365786','contact:phone','1-871-480-5984'
put 'customer','bailey_bob_7073092045','address:city','Graysonfurt'
put 'customer','bailey_bob_7073092045','address:state','NV'
put 'customer','bailey_bob_7073092045','address:street','Hodkiewicz Glens'
put 'customer','bailey_bob_7073092045','address:zip','45250'
put 'customer','bailey_bob_7073092045','cc:number','1228-1221-1221-1431'
put 'customer','bailey_bob_7073092045','cc:expire','2024-06-12'
put 'customer','bailey_bob_7073092045','cc:type','mastercard'
put 'customer','bailey_bob_7073092045','contact:phone','1-828-193-0549'
Reading Data from HBase
There are two operations you can perform to read data from HBase: get and scan.
The get operation allows you to get information from a specific rowkey. The general syntax of a get operation is as follows:
get ‘<table_name’>, ‘<rowkey>’, ‘<information>’
For example, the following query returns the credit card type of Alice Armstrong.
get 'customer', 'armstrong_alice_8570365786', 'cc:type'
You can also get all the information in a given column family.
get 'customer', 'armstrong_alice_8570365786', {COLUMN => 'address'}
If you omit the information field, you can also get all the information of a specific key across all column families.
get 'customer', 'armstrong_alice_8570365786'
It is important to note, however, that the get operation only returns information about a single rowkey. To look for information across row keys, you will need to perform a scan operation. For example, the following query looks for all cities whose rowkey begins with armstrong.
scan 'customer', {STARTROW => 'armstrong_', ENDROW => 'armstronh', COLUMN => 'address:city'}
Conclusion
HBase is a fast and durable database based on Google Big Table and built on top of the Hadoop ecosystem. It gives users full control over where their data is stored and how the system stores and groups together that data. The architecture takes advantage of HDFS' durable and fault-tolerant file system while also utilizing cluster memory to speed up queries.
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
