Write a MapReduce App with Hadoop Streaming
This guide covers how to use Hadoop's core MapReduce functionality, allowing you to write a MapReduce application in any programming language.
Oct 8, 2020 • 4 Minute Read
Introduction
Hadoop Common (originally Hadoop Core) is a collection of the core components of any Hadoop ecosystem. These common libraries and services support other members of the Hadoop ecosystem. There are two components that make up basic Hadoop functionality: a distributed storage known as HDFS and a distributed compute known as MapReduce.
This guide will show you how to utilize Hadoop's core MapReduce functionality using the Hadoop streaming tool. This will allow you to write a MapReduce application in any programming language, so long as it has a mapper and reducer function.
Review of MapReduce
The MapReduce framework is the basis for the majority of data-intensive frameworks today. The following diagram illustrates a basic MapReduce wordcount process.
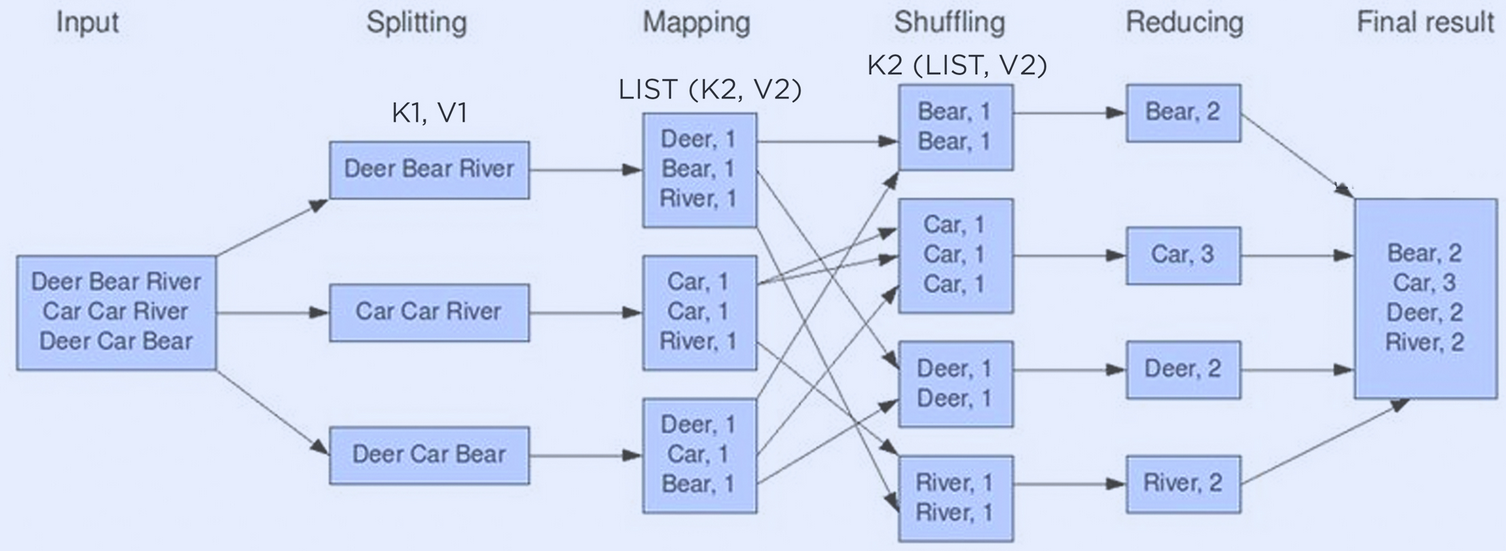
The corpus of text is first separated into the initial <key,value> pair. With text as the input, the initial <key,value> pair is the line and the contents of the line. Afterwards, the mapper function divides those initial <key,value> pairs into intermediate key value pairs. In this case, each instance of a word is mapped to the value 1. The shuffle phase then sorts each of the <key,value> pairs by key, so that the reducer can take care of aggregating the pairs for the final result.
MapReduce Code
The Hadoop Streaming utility allows you to submit an executable in any language, so long as it follows the MapReduce standard. This will allow you to write raw MapReduce code without an abstraction layer.
The following is an example of a mapper function called wordSplitter.py, which separates each word in a line into a <key,value> pair. The code loops through every word in a given line and returns a tab-separated word and number pair. The keyword LongValueSum signals to Hadoop's built-in aggregate reducer that the values in the pair need to be totaled.
#!/usr/bin/python
import sys
import re
def main(argv):
pattern = re.compile("[a-zA-Z][a-zA-Z0-9]*")
for line in sys.stdin:
for word in pattern.findall(line):
print("LongValueSum:" + word.lower() + "\t" + "1" )
if __name__ == "__main__":
main(sys.argv)
Below is an example of a reducer.py function. What this function does is maintain a running total per key. Since all the data is sorted by key, the aggregation is considered complete once the function reaches the last instance of a particular key. After it reaches that last key, Hadoop Streaming can then call the reducer function for the next key, and so on.
#!/usr/bin/env python
import sys
last_key = None
running_total = 0
for input_line in sys.stdin:
input_line = input_line.strip()
this_key, value = input_line.split("\t", 1)
value = int(value)
if last_key == this_key:
running_total += value
else:
if last_key:
print( "%s\t%d" % (last_key, running_total) )
running_total = value
last_key = this_key
if last_key == this_key:
print( "%s\t%d" % (last_key, running_total) )
However, for simple aggregations like wordcount or simply totalling values, Hadoop has a built-in reducer called aggregate. The following is an example of a script that runs a Hadoop Streaming job using a custom mapper but built-in aggregate reducer.
hadoop-streaming -mapper wordSplitter.py \
-reducer aggregate \
-input <input location> \
-output <output location> \
-file myPythonScript.py # Location of the script in HDFS, S3, or other storage
The wordSplitter.py file should be stored in your distributed storage, normally HDFS or Amazon S3. The location of the file should then be passed as an argument to hadoop-streamin. If you're using a custom reducer, you will also need to pass in the custom reducer script.
Conclusion
Hadoop Streaming is one of the first things aspiring Hadoop developers learn. It provides a simple interface to write MapReduce code, however, it takes away the abstraction layer of Hive or Pig by forcing the developer to write raw MapReduce code. It is one of Hadoop's core components and should be present in any and all Hadoop deployments and distributions.
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
