Data Stream Management with Apache Kafka Streams
Looking for a solution to manage tons of data from several sources? Kafka is streaming platform that is extremely capable of managing variable rates of incoming data efficiently in a fault-tolerant and scalable manner. Learn more about it today!
Jan 10, 2019 • 21 Minute Read
Introduction
Apache Kafka is a distributed streaming platform that is effective and reliable when handling massive amounts of incoming data from various sources heading into the numerous outputs.

When using Kafka using proper deployment and configuration schemes, our precious input data will be replicated across several nodes, ensuring that our cluster will be up and running in case of a catastrophe, such as a hardware failure in one of our nodes.

Given various input rates, we can also easily scale our cluster in order to adjust to our changing requirements.

Apache Kafka (from now on I will omit the “Apache”, but I am always referring to the official Apache Kafka release) makes all these “real-life” problems easy to solve, and it does so efficiently and with great speed.
In short, Kafka is extremely capable of managing variable rates of incoming data efficiently in a fault-tolerant and scalable manner.
That sounds to me like a great tool for the toolbox!
Kafka Streams is a client library which provides an abstraction to an underlying Kafka cluster, and allows for stream manipulation operations to be performed on the hosting client. The abstraction provided for us is load-balanced by default, making it an interesting candidate for several use cases in particular.

Sound interesting? Well, let’s get started!
Batch Processing? Real-time Processing? How About Something New?
The world of data has changed vastly over the last decade, or even more.
Data was once local to a single machine; it's now shared on multiple machines, computer networks, and even network domains (hosted on multiple datacenters).
In short, data management systems have gone from being centralized to being widely distributed.

Several software domains have evolved and matured as distributed architecture has become more common. These changes are now allowing us to present software solutions which are highly scalable and fault-tolerant while also opening up more aspects to consider when problem solving, such as concurrency, distributed transactions, and more.

The evolution of our data and data analysis platforms has left us with some very interesting solutions to problems we’ve encountered along the way.
For example, today, we know how to process massive amounts of data in batches. There are even specific file systems built for the task of holding very large files (e.g. HDFS). We have even developed various techniques and methodologies (e.g. MapReduce) which allow us to break down (suitable) problems into smaller problems and perform calculations in parallel - in order to present results faster.

Then, we’ve also learned how to overcome limits when talking about incoming data — we’ve distributed our data analysis platforms gates and were able to consume more input than we previously have. We usually refer to such input consumption as “online” or (mistakenly) “real-time” data consumption. (I will use the more accurate “online” term.)
Between the world of (“offline”) batch processing and “online” processing, there grew an entire domain of synchronization between the information we are learning “online” and the information we are required to process “offline” (and usually refer to in our “online” calculations).
In this domain, we were presented with ETL processes, DevOps scripts, and even manual (daily, weekly, ...) tasks that need be done in order to keep our system’s reference data up-to-date.

The use cases I’ve just mentioned will certainly benefit from using Kafka Streams.
In the first use case, we could use Kafka Streams in order to consume the data stored in our (e.g. HDFS volume) storage and pass it forward to workers, which will then perform a computation on it.

In the second use case, we could use Kafka Streams in order to create an enrichment mechanism for all of our incoming data. For example, adding a unique system ID to incoming event data or attaching a context object to incoming event data.
Before we look at additional use cases together with code samples, let’s first review the features of the Kafka Streams API.
What’s in the Box
Ok, let’s talk about the box first.
The “box”, in the case of Kafka Streams, is the same “box” you already know and are familiar with. Kafka Streams is a feature integrated within Kafka, since recent versions. No separate download is required. You get everything you need with the download.
Accessing the Streams API, via any java application is as simple as adding the relevant dependency in any “standard” desirable manner (e.g. maven, gradle or even direct jar dependency). In the screenshot below, you can see an example Maven dependency:
Now, its being a standard Java library actually means your development environment, as well as deployment target, is limited only by the target's ability to host a JVM. In other words, you are almost unlimited :-). Windows, Mac, and Linux will gladly host and run your application either directly or in a container, such as Docker.
The Streams API client will be hosted in your application, but it’s important to note another aspect of the client - all computation is done in process, inside your client hosting application and not on the Kafka cluster. It is very important to remember that, so I’ll repeat it again:

The Kafka Streams client performs all of his work inside of your application and not the Kafka cluster.
And why is that? Simply because your Kafka cluster is already busy enough :-).
So you might ask me if there is additional overhead for working with the Streams client.
Yes, there is overhead.
However, in many cases, that overhead will depend on the specific manner in which you manipulate your data and can be kept to a minimum.
Other than ease of development and ease of deployment, and precisely because all computation is performed on the client applications, Kafka Streams applications do not require a dedicated compute cluster (e.g. Apache Spark). All you do is point at your existing Kafka cluster and define what (data) transformations and enrichments you would like to do.
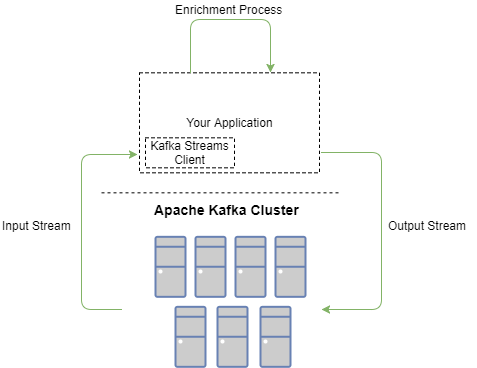
Here, at the diagram below, you can see, that a client application defines a message stream from the topic “CheckoutRequest”. It then enriches the request with additional data, and passes it to an outgoing stream,”EnrichedCheckoutRequest”, for further processing by processes listening to the “EnrichedCheckoutRequest” stream.

Scalable, fault-tolerant, secure
One more point to consider when considering using Kafka Streams, is that it comes with Kafka's promises of scalability, fault-tolerance and security.
As all of the data is being managed by the Kafka cluster in relevant Kafka topics, we enjoy Kafka's maturity with managing our data safely.
Exactly-once processing
These all seemed like great reasons for using the Kafka Streams API. However, I saved the best for last.
With Kafka Streams' latest versions, you will enjoy an exactly-once processing semantics system.
That is nothing less than front page news!
With distributed messaging systems there are several semantics. I will enumerate the most common:
- At-least-once
- At-most-once
- Exactly-once
What I am about to explain now, assumes that all Kafka topics in our cluster, even if at faulted state, will eventually become available.

With at-least-once processing, we are assured that any given message will get to a consumer at least once (as the name implies). A message getting to a consumer more than once will probably be due to a producer retrying to create an unacknowledged message, though other scenarios may be valid as well.

With at-most-once, we are basically sending a message and might (due to a cluster problem) consider it transmitted even if it hasn't reached its destination safely.

But only with exactly-once can we be sure that a message will arrive and be acknowledged by a consumer once and only once per stream message.
And that is a most powerful capability in a distributed messaging system. It leaves the developer free to think about the task and simply assume that a transmitted stream message will arrive to a stream consumer.
So powerful, exactly-once processing semantics gives Kafka even more use cases — conditions which before Kafka would have otherwise forced us to “safeguard” our entries to prevent duplicate message processing, or additional retry mechanism to make sure all messages has been passed successfully.
For additional overview of Apache Kafka, including Producers and Consumers, along with sample code, please check out my Pluralsight course here.
Let’s talk about such use cases.
Interprocess Communication Infrastructure for Your Software Platform
The first use case that comes in mind (for me, that is) is a scalable and reliable interprocess communication mechanism for your software platform services.
The first interprocess paradigm that pops to mind is the most popular publisher / subscriber mechanism.
This paradigm allows us to have a microservice or numerous microservices produce messages into a Kafka Stream (e.g “PrintRequest”). This Stream will then be consumed by other microservices.

This will allow us to have multiple producers and multiple consumers for the Kafka Stream “PrintRequest”. And utilizing the exactly-once semantics, we could make sure that any “PrintRequest” message will be delivered once and only once to a proper consumer.

Sounds good, right? It might actually remind you of using Kafka Producers and Kafka Consumers with a Consumer group!
Indeed, the Kafka Stream performs the load-balancing for us, perhaps a bit better than what we could have implemented at a lower abstraction level.
"So I'm working with a higher abstraction level and getting exactly-once message delivery guarantees? Well ... I'm in!"
Let’s observe how such code would like like, utilizing the Kafka Streams API.
Stream Message Consumers Code Sample
In the below example you can see how a Kafka Stream is created with its source being the “PrintRequest” topic.
After it's created, we are able to consume all messages as a key-value pair and process as we desire.

Pretty straightforward, right?
I would like to remind you, that you can (and should) spawn multiple stream message producers and consumers*. Messages will be delivered and load balanced for you.
*Please do not confuse the terms “producer” and “consumer” with the lower level Kafka producers and consumers.
With Kafka, a producer and consumer are in the context of a topic. With the Streams API, I am mentioning “producer” and “consumer” in the context of an abstract data stream. While data streams are eventually implemented with topics, I highly recommend putting this knowledge aside (only for a while) while trying to get used to the stream abstraction.
Let’s observe an additional code sample now. Consider the case in which we are receiving a stream message and would like to transform that message and send it down another stream.
Stream Message Consumption, Transformation and Production Code Sample
In the code sample below, you can see that per each message received, we produce a message to the topic “EnrichedPrintRequest” after performing a minor manipulation on the message key.
In this case, I’ve prefixed every PrintRequest message key, with the current month.

Ok, this is starting to get interesting! So we are outside of our Kafka cluster and are doing data transformations in a scalable and fault-tolerant manner, all the while enjoying the benefits (e.g security) that we get when inside of a Kafka cluster? Magic :-)
But seriously, that is exactly what you are doing — you are hosting your Kafka Streams application in your own process, and, using the Streams API, you are getting message-handling services from the underlying capabilities of the Kafka Streams client. And the Kafka Streams client, in turn, “knows” how to properly “break down” the abstracted stream and stream application into the terms of the Kafka cluster which deals with topics.
Going back to the use case we are discussing, implementing an interprocess communication infrastructure with Kafka Streams API, you can now understand how that can be done.
But let’s describe a real life scenario.
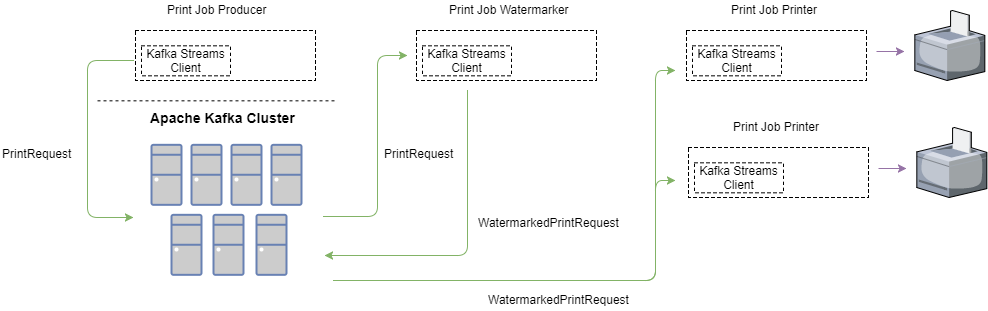
Below, you can see a sample of a service which is responsible to receive print jobs. It needs to watermark each print job, and pass it onto a printing service, which has access to a physical printer. Simple enough, right?

Now, let’s imagine our business grew, and we purchased additional printers, which we would like to utilize.
All we have to do, is deploy additional printer proxy services, and they will start taking on job requests. Cool, right?
Event-driven Micro Services Architected Platform State Representation
With direct connection to the previous use case, and due to the nature of Kafka, specifically that topics are persisted to a replicated commit log, I would like to propose an additional use case or maybe even an additional infrastructure component implemented with Kafka Streams.
State representation in an event-driven, microservices-architected platform.

In a microservice architecture, we are trying to keep state outside of our service. We do that, mostly in order to be able to scale our platform. If a service instance has no state, and it only responds to arriving messages - then any other instance of that service can be agnostic to that instance and handle messages arriving at it’s gate(S), right?
Well, that is a simplification, but in general - being stateless as a service is an enabler for multi-instance deployment.
The Streams API, in particular when using the exactly-once semantics, can be a very strong complementary tool. In particular, it allows us to get rid of the session abstraction whenever it's unnecessary. This eliminates redundant overhead.
Let’s think about the following use case:
Use Case Analysis via User Cart Management
We have a user. That is a good thing :-).
Our user would like to add an item to his shopping cart.
He clicks on the “Add Item” button, next to the item he wants.

This is what happens behind the scenes:
- The UI fires an “AddItemRequest” message event to the back-end.
- A Process, named “AddItemManager”, which listens to the “AddItemRequest” stream, receives the “AddItemRequest” message and validates it.
- If the message is valid, it send a message to the “AddItemValidatedRequest” stream.
- If the message is invalid, it send a message to the “AddItemInvalidRequest” stream
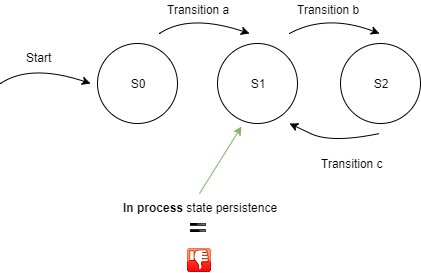
Now, this is pretty much a state-machine, right? Messages are our state transitions in this state-machine, and services are the initiators of state transitions.
However, no state is persisted in our running, thereby potentially crashing services. Instead, all of our state, represented as messages, is persisted (and replicated) securely in our Kafka cluster!
In case of system downtime, no state data is lost. Once our system is up and running again, relevant services will pick up working again. From the services point of view, no state exists. They are unaware of “the bigger picture”.
Cart management is just an abstraction we, humans, are using, in order to describe the valid transitions between logical states in our process.
This was just a simple example for how simple things can become with proper infrastructure and system architecture.
If you’re already dealing with microservices and thus abide by the rules that a microservices architecture lives by, Kafka Streams should definitely be a tool in your infrastructure toolbox!
Think about it.
Conclusion
This “bumpy road” we’ve just walked together started with discussing the advantages of Kafka and eventually discussing familiar use cases such as batch and "online" stream processing in which Stream processing, particularly with the Kafka Streams API, make life easier.
At this point, I pivoted towards a couple of related use cases that I felt could be addressed by Kafka Streams, in particular the Kafka Streams client.
We discussed the ability to utilize Kafka Streams as an interprocess communication mechanism for any distributed platform.
I also mentioned the straight forward usage of the Kafka Streams client in order to implement a state persistence and delivery mechanism in an event-driven microservices platform.
I am certain that the diligent reader will be able to find even more use cases for the persisted, scalable, and fault-tolerant data-streaming mechanism that is Kafka Streams.
Thank you for joining me on this journey. Hopefully, you found the article interesting and will look to deploy Kafka Streams in the near future. Feel free to drop me any questions or comments, and add this guide to your favorites!
Kobi.
Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
