
- Course
Data Engineering with AWS Machine Learning
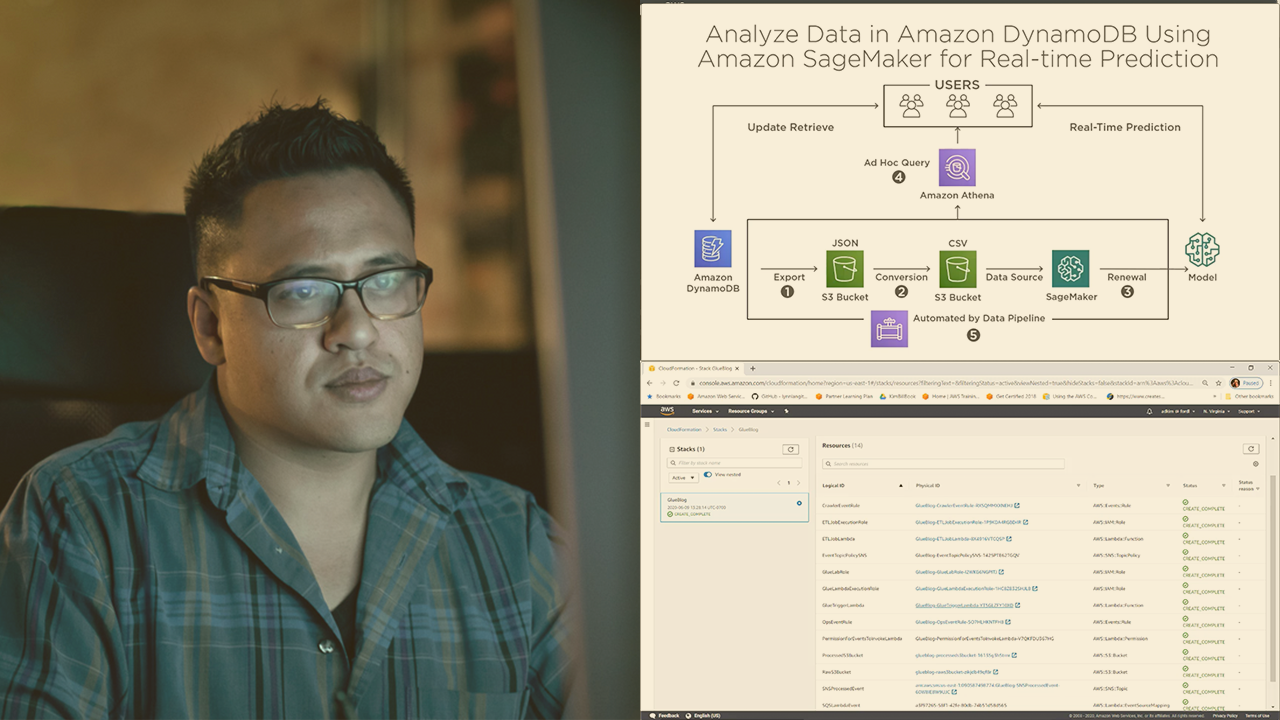
The whole field of machine learning revolves around data. This course will teach you how to properly choose between the various AWS data repositories, ingestion services, and transformation services in a cost-effective, best-practice manner.
Intermediate
- Course
Data Engineering with AWS Machine Learning
The whole field of machine learning revolves around data. This course will teach you how to properly choose between the various AWS data repositories, ingestion services, and transformation services in a cost-effective, best-practice manner.
Intermediate
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Cloud
What you'll learn
Storing data for machine learning is challenging due to the varying formats and characteristics of data. Raw ingested data must first be transformed into the format necessary for downstream machine learning consumption, and once the data is ready to be used, it must be ingested from storage to the machine learning service. In this course, Data Engineering with AWS Machine Learning, you’ll learn to choose the right AWS service for each of these data-related machine learning ML tasks for any given scenario. First, you’ll explore the wide variety of data storage solutions available on AWS and what each type of storage is used for. Next, you’ll discover the differing AWS services used to ingest data into ML-specific services and when to use each one. Finally, you’ll learn how to transform your raw data into the proper formats used by the various AWS ML services. When you’re finished with this course, you’ll have the skills and knowledge of how to properly provide data solutions for storing, preparing, and ingesting data needed to architect data engineering solutions on AWS for Machine Learning, and be prepared to take the AWS Machine Learning Certification exam.
Data Engineering with AWS Machine Learning
Intermediate
Table of contents
-
Important Data Characteristics to Consider in a Machine Learning Solution | 1m 47s
-
Choosing an AWS Data Repository Based on Structured, Semi-structured, and Unstructured Data Characteristics | 1m 39s
-
Choosing AWS Data Ingestion and Data Processing Services Based on Batch and Stream Processing Characteristics | 1m 29s
-
Refining What Data Store to Use Based on Application Characteristics | 2m 22s
-
Module Summary for the ML Exam and Segue into Next Topics | 41s
Kim Schmidt is an AWS Partner & Vendor. She's worked for or with Dun & Bradstreet, Google, Microsoft, & AWS. Kim is currently writing a book "Artificial Intelligence & Analytics on AWS."
