
- Course
Architecting Production-ready ML Models Using Google Cloud ML Engine
This course covers Cloud ML Engine, a powerful service that supports distributed training and evaluation for models built in TensorFlow, Scikit-learn and XGBoost.
Intermediate
- Course
Architecting Production-ready ML Models Using Google Cloud ML Engine
This course covers Cloud ML Engine, a powerful service that supports distributed training and evaluation for models built in TensorFlow, Scikit-learn and XGBoost.
Intermediate
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Cloud
What you'll learn
Building machine learning models using Python and a machine learning framework is the first step towards building an enterprise-grade ML architecture, but two key challenges remain: training the model with enough computing firepower to get the best possible model and then making that model available to users who are not data scientists or even Python users. In this course, Architecting Production-ready ML Models Using Google Cloud ML Engine, you will gain the ability to perform on-cloud distributed training and hyperparameter tuning, as well as learn to make your ML models available for use in prediction via simple HTTP requests. First, you will learn to use the ML Engine for models built in XGBoost. XGBoost is an ML framework that utilizes a technique known as Ensemble Learning to construct a single, strong model by combining several weak learners, as they are known. Next, you will discover how easy it is to port serialized models from on-premise to the GCP. You will build a simple model in scikit-learn, which is the most popular classic ML framework, and then serialized that model and port it over for use on the GCP using ML Engine. Finally, you will explore how to tap the full power of distributed training, hyperparameter tuning, and prediction in TensorFlow, which is one of the most popular libraries for deep learning applications. You will see how a JSON environment variable called TF_CONFIG is used to share state information and optimize the training and hyperparameter tuning process. When you’re finished with this course, you will have the skills and knowledge of the Google Cloud ML Engine needed to get the full benefits of distributed training and make both batch and online prediction available to your client apps via simple HTTP requests.
Architecting Production-ready ML Models Using Google Cloud ML Engine
Intermediate
Table of contents
-
Module Overview | 54s
-
Prerequisites and Course Outline | 2m 34s
-
Introducing Google Cloud ML Engine | 4m 47s
-
ML Engine and ML Frameworks | 4m 25s
-
Python Package Structure | 1m 47s
-
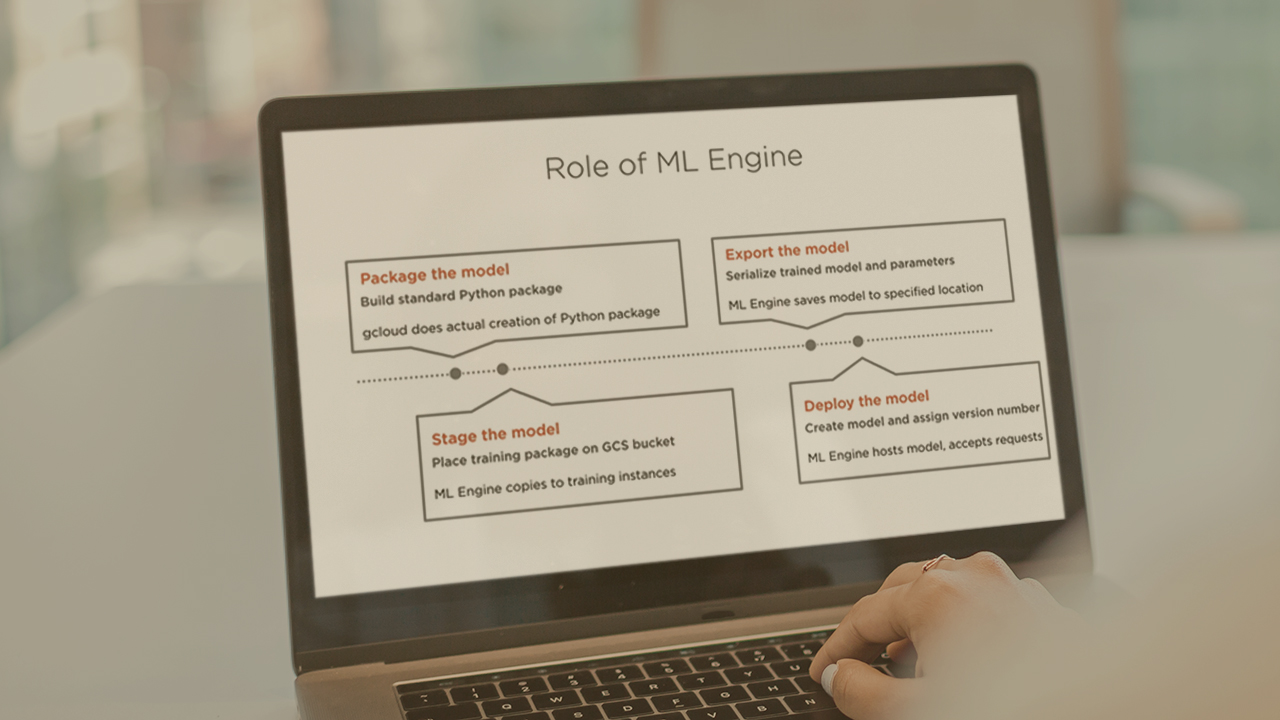
Training and Deploying Models | 3m 33s
-
ML Engine Pricing: Scale Tiers and Training Units | 6m 49s
-
ML Engine Pricing: Online and Batch Prediction | 3m 37s
An engineer and tinkerer, Vitthal has worked at Google, Credit Suisse, and Flipkart and studied at Stanford and INSEAD. He has worn many hats, each of which has involved writing code and building models. He is passionately devoted to his hobby of laughing at his own jokes.
