
- Course
Handling Streaming Data with a Kafka Cluster
This course will teach you how to handle different scenarios that are commonly encountered when using a streaming platform inside your organization.
Intermediate
- Course
Handling Streaming Data with a Kafka Cluster
This course will teach you how to handle different scenarios that are commonly encountered when using a streaming platform inside your organization.
Intermediate
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Data
What you'll learn
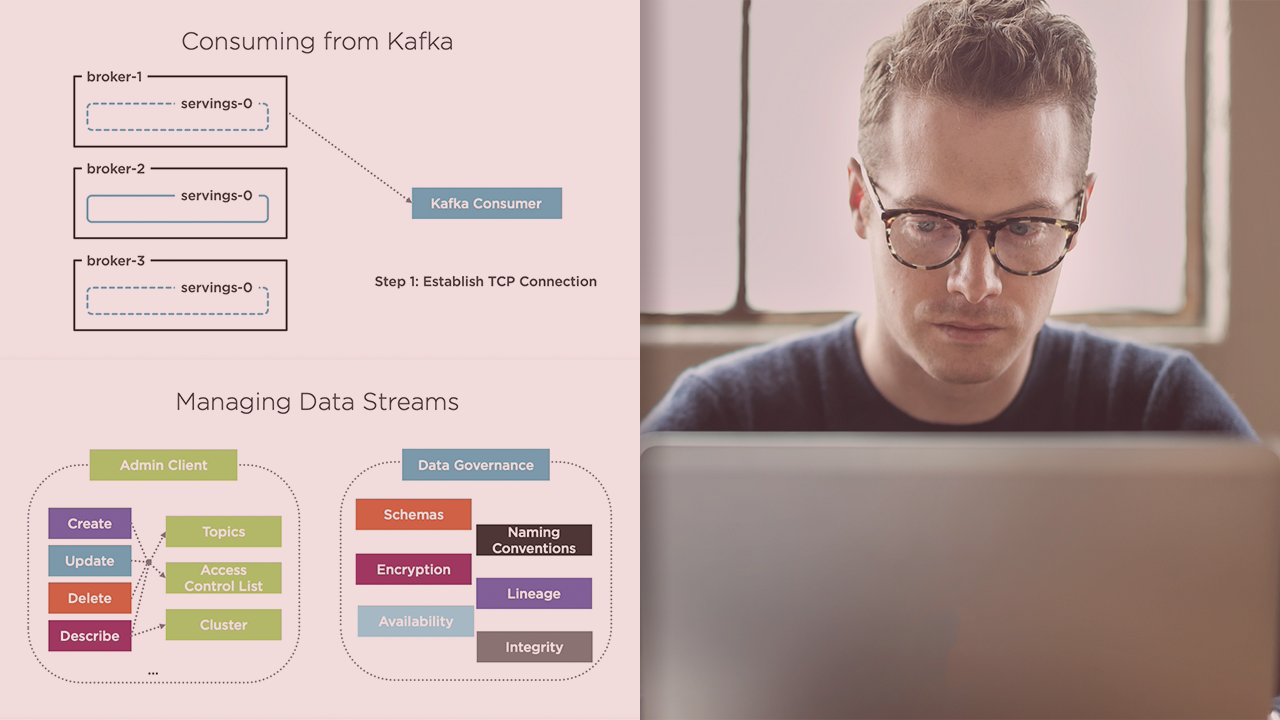
There are a lot of common scenarios that occur when using a streaming platform inside an organization. In this course, Handling Streaming Data with a Kafka Cluster, you’ll learn to handle a variety of different scenarios you may encounter. First, you’ll explore why Kafka makes such a great solution for handling streaming data while exploring different options in terms of optimizations and integrations with other models. Next, you’ll discover how to manage your data and perform various operations against your Kafka Cluster. Finally, you’ll learn how to secure the data streams by applying different techniques. When you’re finished with this course, you’ll have the skills and knowledge of handling streaming data with Apache Kafka needed to build and manage streaming pipelines in your organization.
Handling Streaming Data with a Kafka Cluster
Intermediate
Bogdan Sucaciu is a Software Engineer at Axual in The Netherlands, where he is taking part in building a Streaming Platform designed to share information in real-time, enabling instant processing of incoming events. He has several years of experience "cooking" software with JVM-based languages, some flavors of web technologies and garnishing with automated testing.
