
- Course
Getting Started with Hazelcast
Learn the fundamentals of Hazelcast for distributed caching and processing.
Intermediate
- Course
Getting Started with Hazelcast
Learn the fundamentals of Hazelcast for distributed caching and processing.
Intermediate
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Core Tech
What you'll learn
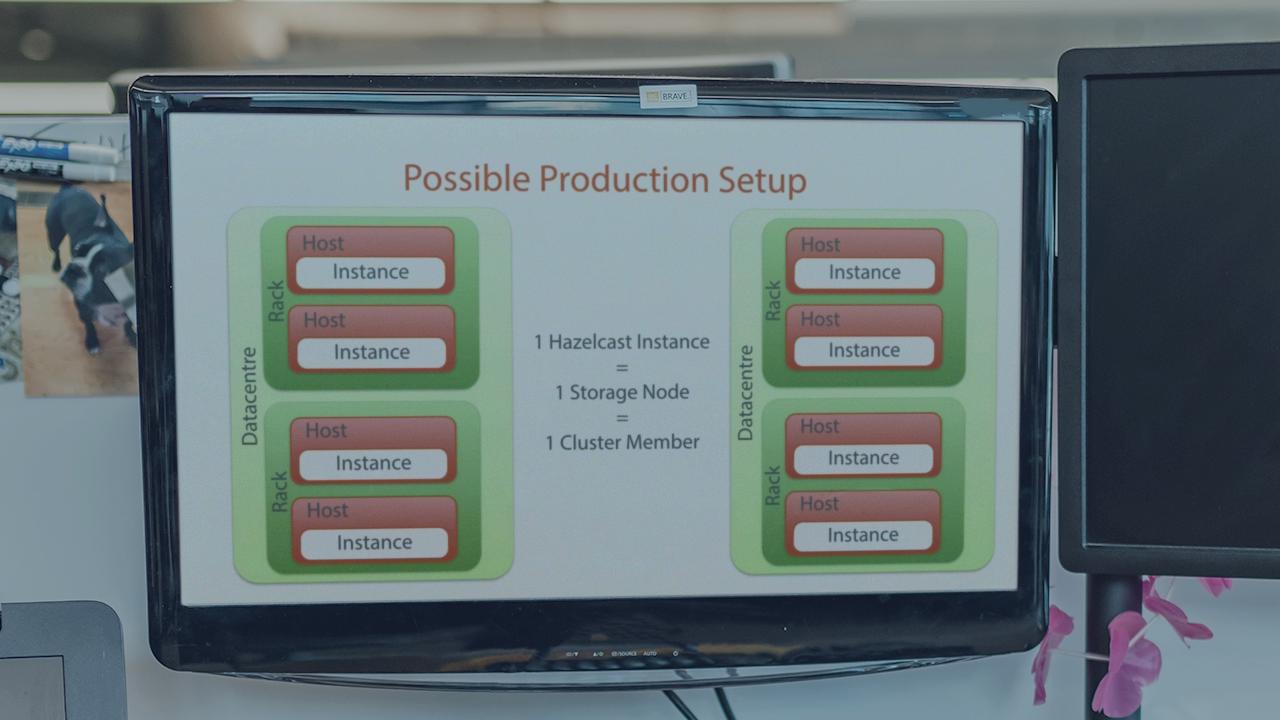
This course covers the base information you need to get up and running with Hazelcast. It covers the main data structures with a focus on distributed maps. It also covers how to ensure that you use you network efficiently and how to debug and monitor your applications.
Getting Started with Hazelcast
Intermediate
Table of contents
Grant is a Software Engineer with over 15 years experience working in mainly large scale, highly available and real time enterprise applications. He is keen on Agile approaches and automation to solve complex problems for clients and stakeholders.
