
- Course
Building Machine Learning Models in Python with scikit-learn
This course course will help engineers and data scientists learn how to build machine learning models using scikit-learn, one of the most popular ML libraries in Python. No prior experience with ML needed, only basic Python programming knowledge.
Beginner
- Course
Building Machine Learning Models in Python with scikit-learn
This course course will help engineers and data scientists learn how to build machine learning models using scikit-learn, one of the most popular ML libraries in Python. No prior experience with ML needed, only basic Python programming knowledge.
Beginner
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- AI
- Data
What you'll learn
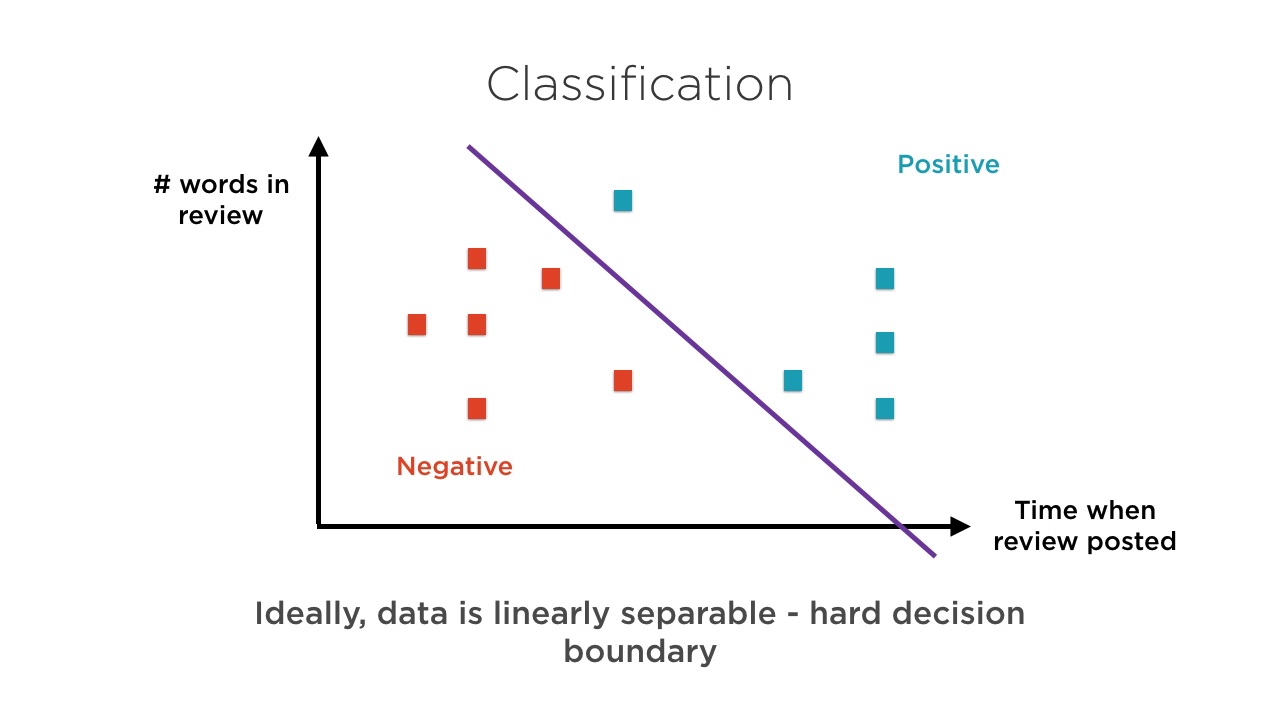
The Python scikit-learn library is extremely popular for building traditional ML models i.e. those models that do not rely on neural networks.
In this course, Building Machine Learning Models in Python with scikit-learn, you will see how to work with scikit-learn, and how it can be used to build a variety of machine learning models.
First, you will learn how to use libraries for working with continuous, categorical, text as well as image data.
Next, you will get to go beyond ordinary regression models, seeing how to implement specialized regression models such as Lasso and Ridge regression using the scikit-learn libraries. Finally, in addition to supervised learning techniques, you will also understand and implement unsupervised models such as clustering using the mean-shift algorithm and dimensionality reduction using principal components analysis.
At the end of this course, you will have a good understanding of the pros and cons of the various regression, classification, and unsupervised learning models covered and you will be extremely comfortable using the Python scikit-learn library to build and train your models. Software required: scikit-learn, Python 3.x.
Building Machine Learning Models in Python with scikit-learn
Beginner
Table of contents
-
Version Check | 16s
-
Module Overview | 1m 34s
-
Prerequisites and Course Overview | 2m 52s
-
Machine Learning Use Cases and scikit-learn | 6m 51s
-
Supervised and Unsupervised Learning Techniques | 6m 20s
-
Demo: Useful Python Packages | 1m 18s
-
Mean and Variance | 5m 14s
-
Demo: Scaling Numeric Data | 3m 29s
-
Categorical Data and One-hot Encoding | 2m 11s
-
Demo: Representing Categorical Data in Numeric Form | 2m 39s
-
Representing Text in Numeric Form | 3m 44s
-
Frequency Based Encoding: Count Vectors | 3m 42s
-
Frequency Based Encoding: TF/IDF | 2m 45s
-
Demo: CountVectorizers, TfidfVectorizer, HashingVectorizer | 5m 22s
-
Representing Images in Numeric Form | 2m 46s
-
Demo: Extracting Features from Images | 4m 45s
A problem solver at heart, Janani has a Masters degree from Stanford and worked for 7+ years at Google. She was one of the original engineers on Google Docs and holds 4 patents for its real-time collaborative editing framework.
