
- Course
Scalable Machine Learning with the Microsoft Machine Learning Server
In this course, you will learn how to create big data machine learning experiments using the Microsoft Machine Learning Server. Detailed code examples in both R and Python demonstrate how to scale your code and work with Apache Spark and SQL Server.
Beginner
- Course
Scalable Machine Learning with the Microsoft Machine Learning Server
In this course, you will learn how to create big data machine learning experiments using the Microsoft Machine Learning Server. Detailed code examples in both R and Python demonstrate how to scale your code and work with Apache Spark and SQL Server.
Beginner
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- AI
- Cloud
- Data
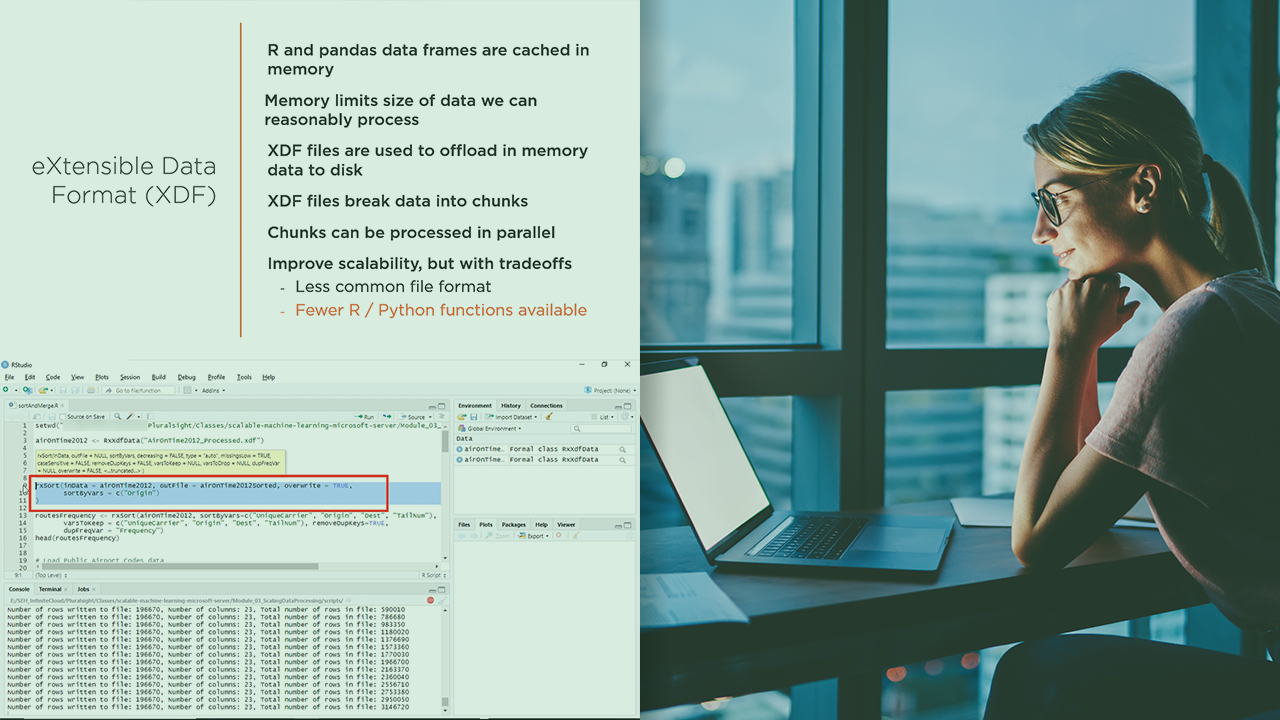
What you'll learn
Working with big data often exceeds the capacity of in-memory dataframes. In this course, Scalable Machine Learning with the Machine Learning Server, you will learn how to build scalable, end-to-end machine learning experiments using both R and Python using the Microsoft Machine Learning Server. First, you will learn how to import, process, transform, and visualize big data. Next, we will cover how to write custom, scalable, distributed functions which can be executed in a number of compute contexts. In addition, you will learn how to use the state of the art machine learning algorithms included in the MicrosoftML package. Then, we will integrate machine learning experiments into SQL Server. Finally, we will cover how to using the machine learning server with Hadoop and Spark, including integration with popular frameworks such as PySpark, SparkR and Sparklyr. We will spin up an HDInsight cluster in Microsoft Azure, and also build a Spark development environment from scracth. When you’re finished with this course, you will have the skills and knowledge needed to build scalable machine learning experiments using R and Python using XDF files, the Hadoop Distributed File System, SQL Server and Apache Spark.
Scalable Machine Learning with the Microsoft Machine Learning Server
Beginner
Table of contents
Shawn has more than twenty-five years of experience as an architect and developer. He is a presenter at technology conferences and blogs as "The Legal BI Guy."
