
- Course
Extracting Structured Data from the Web Using Scrapy
Data analysts and scientists are always on the lookout for new sources of data, competitive intelligence, and new signals for proprietary models in applications. The Scrapy package in Python makes extracting raw web content easy and scalable.
Beginner
- Course
Extracting Structured Data from the Web Using Scrapy
Data analysts and scientists are always on the lookout for new sources of data, competitive intelligence, and new signals for proprietary models in applications. The Scrapy package in Python makes extracting raw web content easy and scalable.
Beginner
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Data
What you'll learn
Websites contain meaningful information which can drive decisions within your organization. The Scrapy package in Python makes crawling websites to scrape structured content easy and intuitive and at the same time allows crawling to scale to hundreds of thousands of websites.
In this course, Extracting Structured Data from the Web Using Scrapy, you will learn how you can scrape raw content from web pages and save them for later use in a structured and meaningful format.
You will start off by exploring how Scrapy works and how you can use CSS and XPath selectors in Scrapy to select the relevant portions of any website. You'll use the Scrapy command shell to prototype the selectors you want to use when building Spiders.
Next, you'll see learn Spiders specify what to crawl, how to crawl, and how to process scraped data.
You'll also learn how you can take your Spiders to the cloud using the Scrapy Cloud. The cloud platform offers advanced scraping functionality including a cutting-edge tool called Portia with which you can build a Spider without writing a single line of code.
At the end of this course, you will be able to build your own spiders and crawlers to extract insights from any website on the web. This course uses Scrapy version 1.5 and Python 3.
Extracting Structured Data from the Web Using Scrapy
Beginner
Table of contents
-
Version Check | 16s
-
Module Overview | 1m 12s
-
Prerequisites and Course Outline | 2m 16s
-
Introducing Scrapy | 5m 15s
-
Install and Set Up Scrapy | 3m 39s
-
The Scrapy Shell | 3m 52s
-
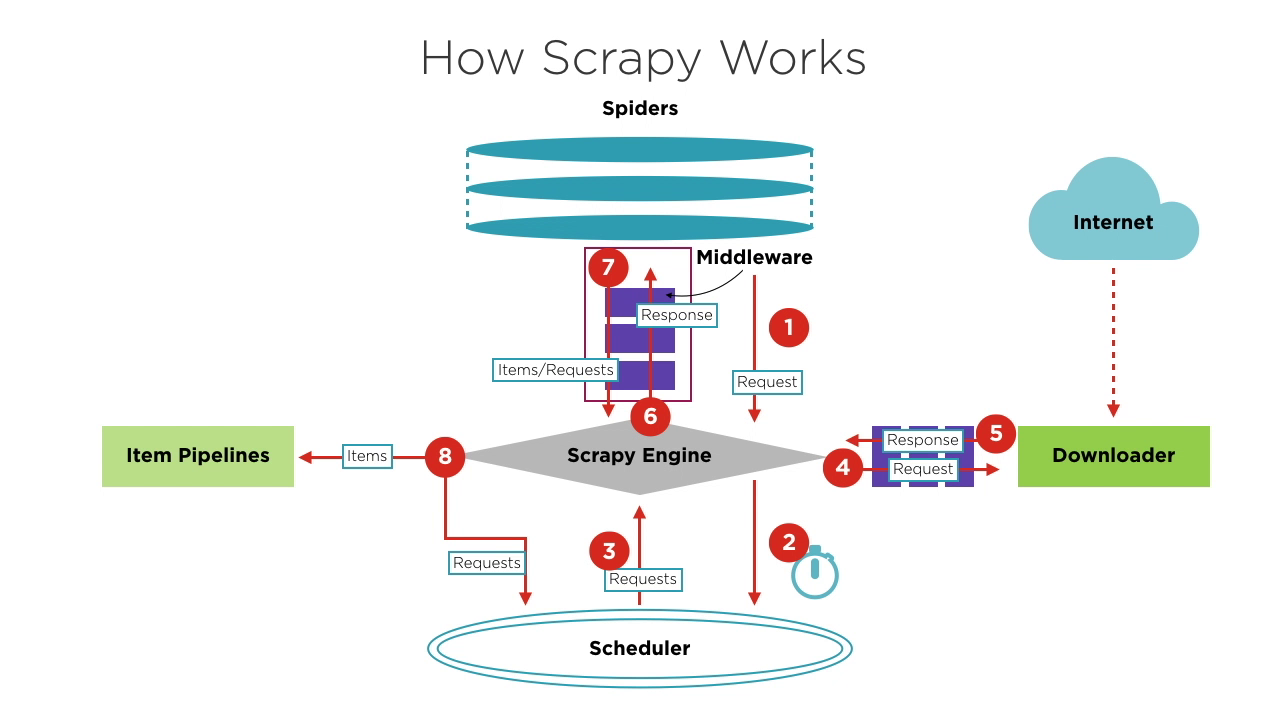
Architecture Overview | 2m 36s
-
Selectors Using CSS Classes | 6m 23s
-
Selectors Using XPath | 2m 38s
-
Using Regular Expressions with Selectors | 3m
A problem solver at heart, Janani has a Masters degree from Stanford and worked for 7+ years at Google. She was one of the original engineers on Google Docs and holds 4 patents for its real-time collaborative editing framework.
