
- Course
Building Machine Learning Models in Spark 2
Training ML models is a compute-intensive operation and is best done in a distributed environment. This course will teach you how Spark can efficiently perform data explorations, cleaning, aggregations, and train ML models all on one platform.
Intermediate
- Course
Building Machine Learning Models in Spark 2
Training ML models is a compute-intensive operation and is best done in a distributed environment. This course will teach you how Spark can efficiently perform data explorations, cleaning, aggregations, and train ML models all on one platform.
Intermediate
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Data
What you'll learn
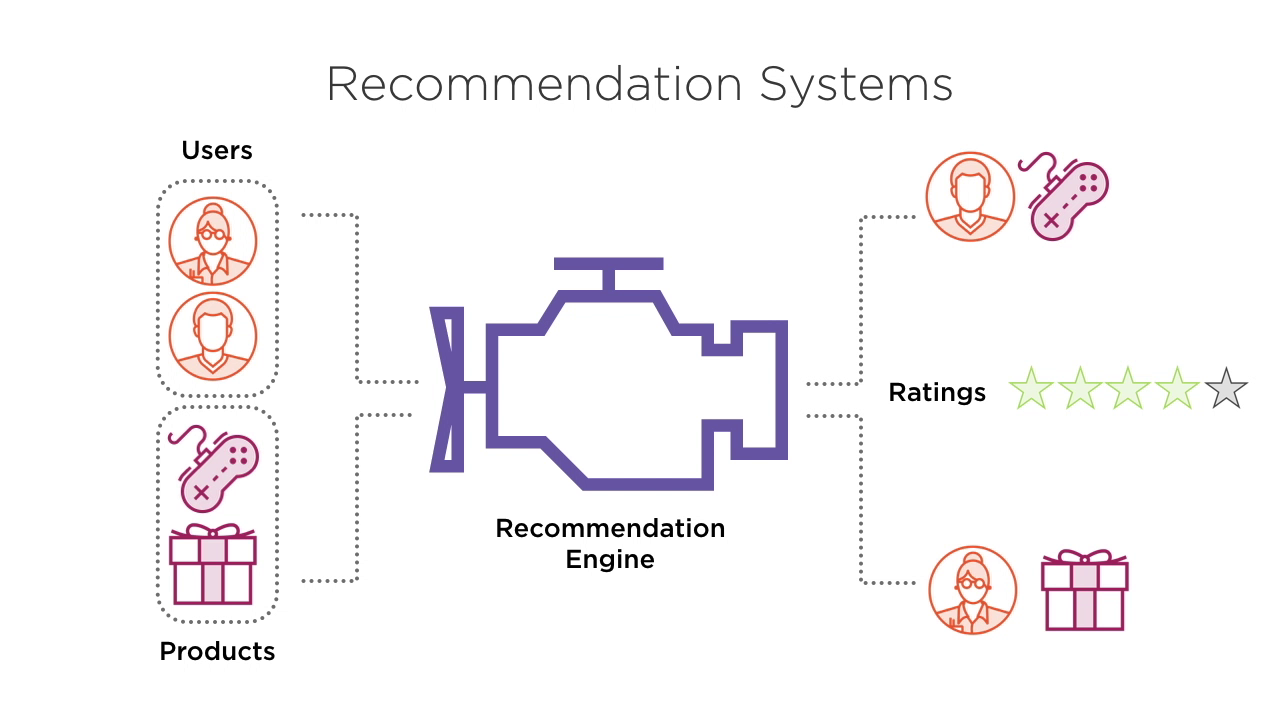
Spark is possibly the most popular engine for big data processing these days. In this course, Building Machine Learning Models in Spark 2, you will learn to build and train Machine Learning (ML) models such as regression, classification, clustering, and recommendation systems on Spark 2.x's distributed processing environment.
This course starts off with an introduction of the 2 ML libraries available in Spark 2; the older spark.mllib library built on top of RDDs and the newer spark.ml library built on top of dataframes. You will get to see the two compared to help you know when to pick one over the other.
You will get to see a classification model built using Decision Trees the old way, and see how you can implement the same model on the newer spark.ml library.
The course covers many features of Spark 2, including going over a brand new feature in Spark 2, the ML pipelines used to chain your data transformations and ML operations.
At the end of this course you will be comfortable using the advanced features that Spark 2 offers for machine learning. You'll learn to use components such as Transformers, Estimators, and Parameters within your ML pipelines to work with distributed training at scale.
Building Machine Learning Models in Spark 2
Intermediate
Table of contents
-
Version Check | 21s
-
Module Overview | 1m 50s
-
Prerequisites and Course Overview | 3m 15s
-
RDDs: The Building Blocks of Spark | 3m 37s
-
DataFrames in Spark 2 | 1m 57s
-
Demo: Spark 2 Installation and Working with Jupyter Notebooks | 4m 25s
-
spark.mllib vs. spark.ml | 4m 35s
-
Introducing Decision Trees | 4m 54s
-
Gini Impurity and Pros and Cons of Decision Trees | 5m 40s
-
Demo: Basic Project Setup | 2m 57s
-
Demo: Wine Classification Using Decision Trees in spark.mllib | 8m 18s
-
Demo: Working with the LIBSVM Data Format | 2m 2s
-
Demo: Decision Trees Using the LIBSVM Data Format | 4m 57s
A problem solver at heart, Janani has a Masters degree from Stanford and worked for 7+ years at Google. She was one of the original engineers on Google Docs and holds 4 patents for its real-time collaborative editing framework.
