
- Course
Getting Started with Spark 2
The 2.x releases of Spark represent significantly different and upgraded features. This course will focus on all of these changes, in both theory and practice.
Beginner
- Course
Getting Started with Spark 2
The 2.x releases of Spark represent significantly different and upgraded features. This course will focus on all of these changes, in both theory and practice.
Beginner
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Data
What you'll learn
Spark is possibly the most popular engine for big data processing these days and the 2.x release has several new features which make Spark more powerful and easy to work with. In this course, Getting Started with Spark 2, you will get up and running with Spark 2 and understand the similarities and differences between version 2.x and older versions. First, you will get to see the basic Spark architecture and the details of Project Tungsten which brought great performance improvements to Spark 2. You will go over the new developer APIs using DataFrames and see how they inter-operate with RDDs from Spark 1.x. Next, you will move on to big data processing where you will load and clean datasets, remove invalid rows, execute transformations to extract insights and perform grouping, sorting, and aggregations using the new DataFrame APIs. You will also study how and where to use broadcast variables and accummulators. Finally, you will work with Spark SQL which allows you to use SQL commands for big data processing. The course also covers advanced SQL support in the form of windowing operations. At the end of this course, you should be very comfortable working with Spark DataFrames and Spark SQL. You will be better equipped to make technical choices based on the performance trade-offs of older versions of Spark vs. Spark 2. Software required: Apache Spark 2.2, Python 2.7.
Getting Started with Spark 2
Beginner
Table of contents
-
Version Check | 21s
-
Module Overview | 2m 4s
-
Prerequisite and Course Outline | 2m 18s
-
Introducing Spark | 3m 44s
-
RDDs: Basic Building Blocks of Spark | 8m 23s
-
RDDs, Datasets, DataFrames: What's the Difference? | 6m 4s
-
Demo: Installing Spark 2 | 4m 29s
-
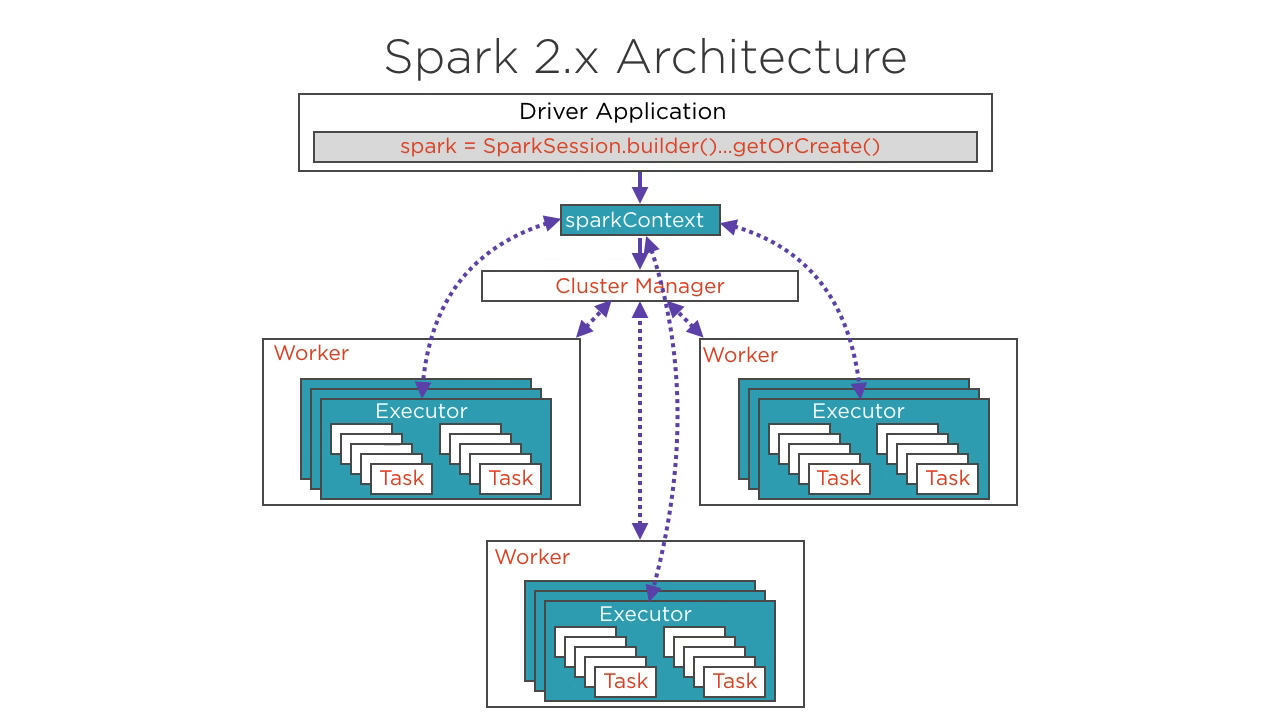
Architecture Overview: Spark 1 and 2 | 6m 29s
-
Demo: Working with RDDs In Spark 2 | 3m 54s
-
Demo: Converting RDDs to DataFrames | 2m 48s
-
Demo: Working with Complex Data Types in DataFrames | 1m 17s
-
Demo: Introducing the SQL Context | 3m 18s
-
Demo: Accessing RDDs in DataFrames | 3m 18s
-
Demo: Spark DataFrames and Pandas DataFrames | 52s
-
Understanding the Differences Between Spark 2 and Spark 1 | 4m 4s
-
Project Tungsten | 5m 36s
A problem solver at heart, Janani has a Masters degree from Stanford and worked for 7+ years at Google. She was one of the original engineers on Google Docs and holds 4 patents for its real-time collaborative editing framework.
