
- Course
Developing Spark Applications Using Scala & Cloudera
Apache Spark is one of the fastest and most efficient general engines for large-scale data processing. In this course, you'll learn how to develop Spark applications for your Big Data using Scala and a stable Hadoop distribution, Cloudera CDH.
Intermediate
- Course
Developing Spark Applications Using Scala & Cloudera
Apache Spark is one of the fastest and most efficient general engines for large-scale data processing. In this course, you'll learn how to develop Spark applications for your Big Data using Scala and a stable Hadoop distribution, Cloudera CDH.
Intermediate
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Cloud
- Data
What you'll learn
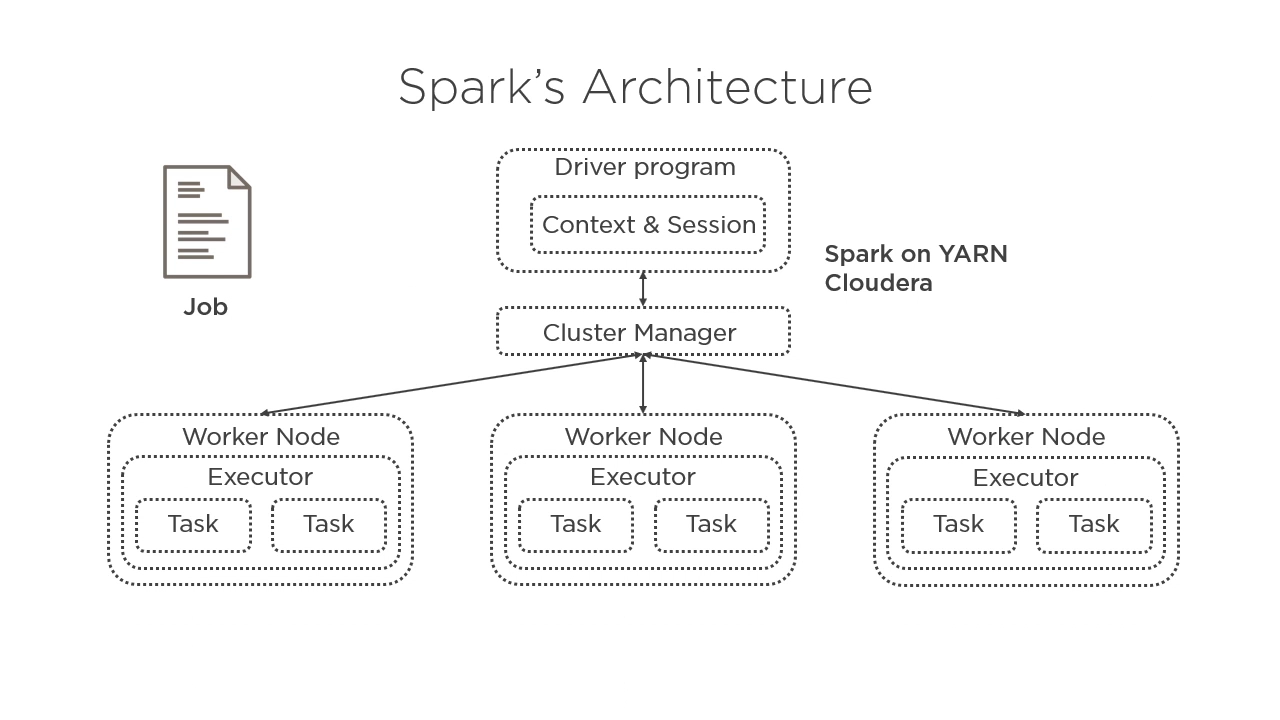
At the core of working with large-scale datasets is a thorough knowledge of Big Data platforms like Apache Spark and Hadoop. In this course, Developing Spark Applications Using Scala & Cloudera, you’ll learn how to process data at scales you previously thought were out of your reach. First, you’ll learn all the technical details of how Spark works. Next, you’ll explore the RDD API, the original core abstraction of Spark. Then, you’ll discover how to become more proficient using Spark SQL and DataFrames. Finally, you'll learn to work with Spark's typed API: Datasets. When you’re finished with this course, you’ll have a foundational knowledge of Apache Spark with Scala and Cloudera that will help you as you move forward to develop large-scale data applications that enable you to work with Big Data in an efficient and performant way.
Developing Spark Applications Using Scala & Cloudera
Intermediate
Table of contents
-
Version Check | 15s
-
Why Spark with Scala and Cloudera? | 1m 8s
-
But Why Apache Spark? | 2m 20s
-
Brief History of Spark | 3m 23s
-
What We Will Cover in This Training | 2m 1s
-
Picking a Spark Supported Language: Scala, Python, Java, or R | 1m 11s
-
What Do You Need for This Course? | 1m 38s
-
Takeaway | 1m 6s
Xavier is very passionate about teaching, helping others understand Generative AI, ML, Search, and Big Data. He is also an entrepreneur, project manager, technical author, trainer, and holds a few certifications with Cloudera, Microsoft, and the Scrum Alliance, along with being a Microsoft MVP.
