
- Course
Language Modeling with Recurrent Neural Networks in TensorFlow
If you are working with text data using neural networks, RNNs are a natural choice for sequences. This course works through language modeling problems using RNNS - optical character recognition or OCR and generating text using character prediction.
Advanced
- Course
Language Modeling with Recurrent Neural Networks in TensorFlow
If you are working with text data using neural networks, RNNs are a natural choice for sequences. This course works through language modeling problems using RNNS - optical character recognition or OCR and generating text using character prediction.
Advanced
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Data
What you'll learn
Recurrent Neural Networks (RNN) performance and predictive abilities can be improved by using long memory cells such as the LSTM and the GRU cell.
In this course, Language Modeling with Recurrent Neural Networks in Tensorflow, you will learn how RNNs are a natural fit for language modeling because of their inherent ability to store state. RNN performance and predictive abilities can be improved by using long memory cells such as the LSTM and the GRU cell.
First, you will learn how to model OCR as a sequence labeling problem.
Next, you will explore how you can architect an RNN to predict the next character based on past sequences.
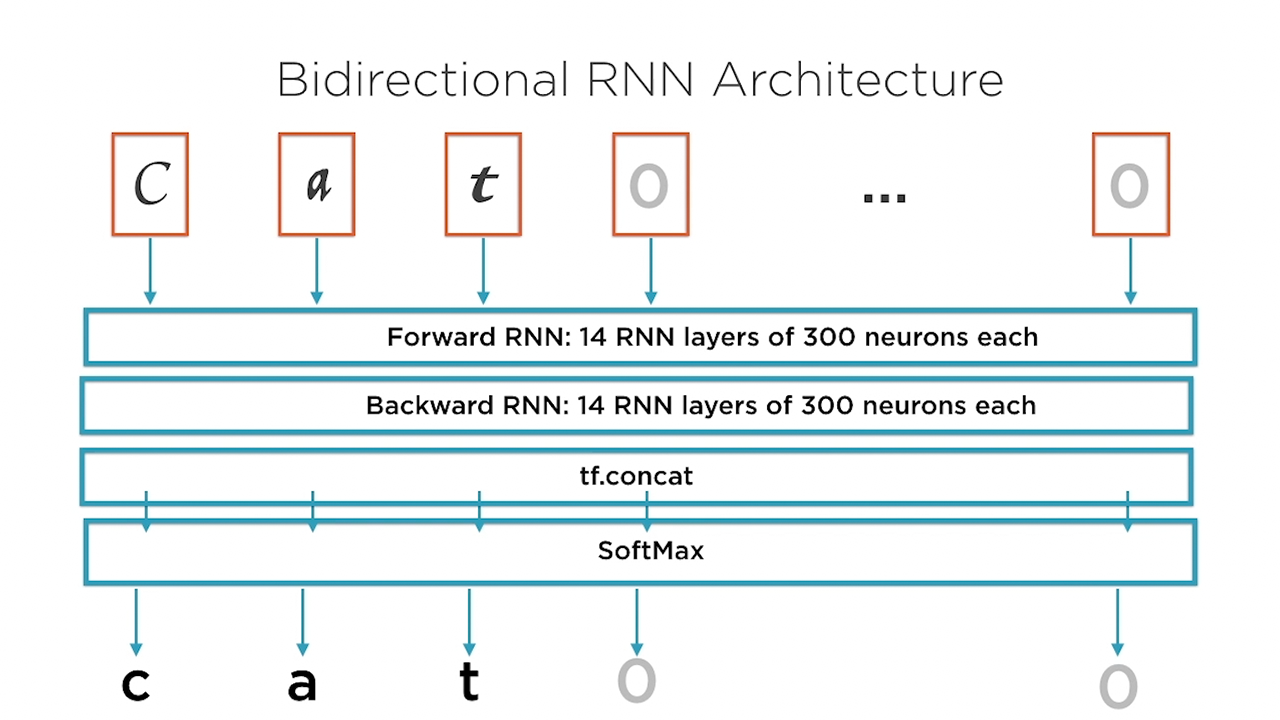
Finally, you will focus on understanding advanced functions that the TensorFlow library offers, such as bi-directional RNNs and the multi-RNN cell.
By the end of this course, you will know how to apply and architect RNNs for use-cases such as image recognition, character prediction, and text generation; and you will be comfortable with using TensorFlow libraries for advanced functionality, such as the bidirectional RNN and the multi-RNN cell.
Language Modeling with Recurrent Neural Networks in TensorFlow
Advanced
Table of contents
-
Version Check | 20s
-
Module Overview | 1m 51s
-
Prerequisites and Course Outline | 2m 10s
-
The Recurrent Neuron | 3m 50s
-
Training a Recurrent Neural Network | 5m 15s
-
The Long Memory Cell | 5m 3s
-
Bidirectional RNNs | 7m 25s
-
OCR: A Sequence Labelling Problem | 3m 37s
-
OCR File Format | 4m 18s
-
Features and Labels for OCR | 2m 4s
-
Conventional RNN Architecture | 5m 18s
-
Bidirectional RNN Architecture | 3m 7s
A problem solver at heart, Janani has a Masters degree from Stanford and worked for 7+ years at Google. She was one of the original engineers on Google Docs and holds 4 patents for its real-time collaborative editing framework.
