
- Course
Introduction to AWS Data Pipeline Patterns and Use Cases
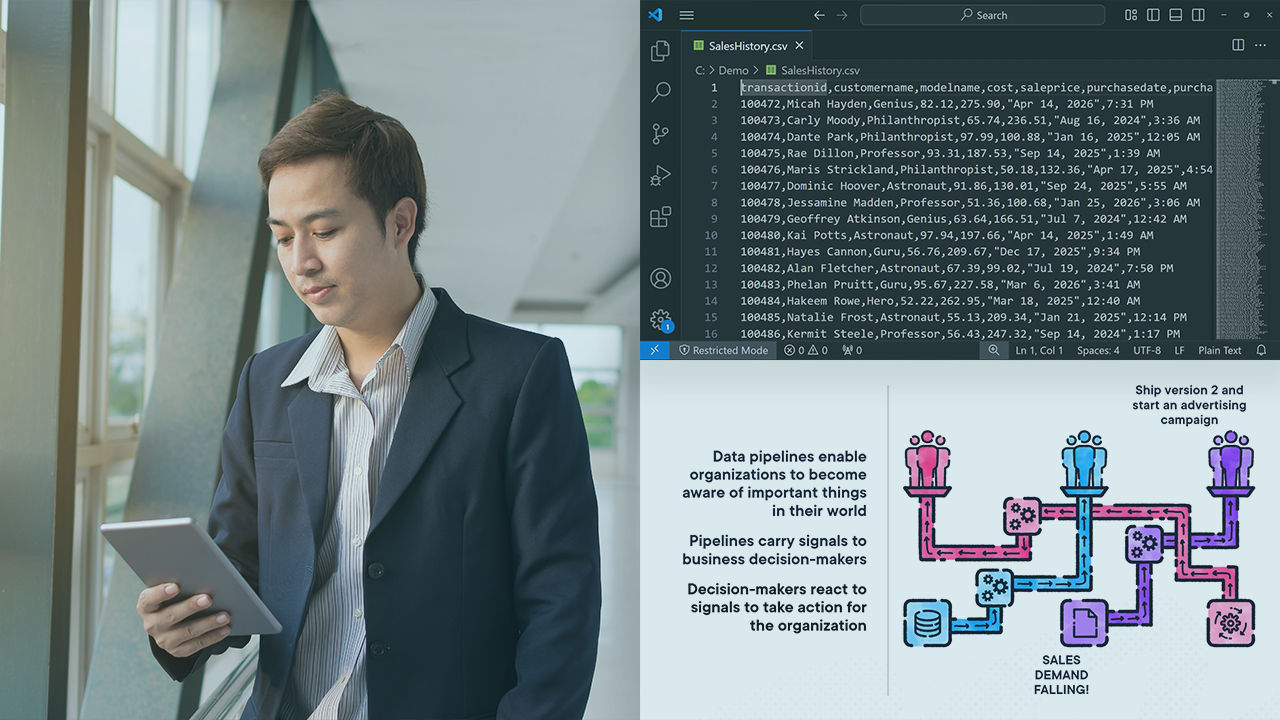
Data Pipelines are the nervous system of an organization, connecting essential business information to decision-makers. This course will introduce you to key pipeline technologies that integrate, process, and deliver business data.
Beginner
- Course
Introduction to AWS Data Pipeline Patterns and Use Cases
Data Pipelines are the nervous system of an organization, connecting essential business information to decision-makers. This course will introduce you to key pipeline technologies that integrate, process, and deliver business data.
Beginner
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Cloud
What you'll learn
Getting started in data analysis requires exploring a set of technologies that are new to many IT professionals. In this course, Introduction to AWS Data Pipeline Patterns and Use Cases, you’ll learn to identify and describe the key concepts in the use of data pipelines. First, you’ll explore batch and streaming pipeline use cases. Next, you’ll discover how data lakes and data warehouses provide support for a pipeline scenario. Finally, you’ll learn how to recognize the role of AWS technologies including AWS Glue, Amazon Redshift, and Amazon EMR in the use of data pipelines. When you’re finished with this course, you’ll have the knowledge of data pipelines needed to understand how pipelines are used in data management.
Introduction to AWS Data Pipeline Patterns and Use Cases
Beginner
Table of contents
Mike Hammond is a seasoned technical trainer with 25 years of experience delivering technical content. His focus is on AWS administration and Windows system administration.
