
- Course
Cleaning Data: Python Data Playbook
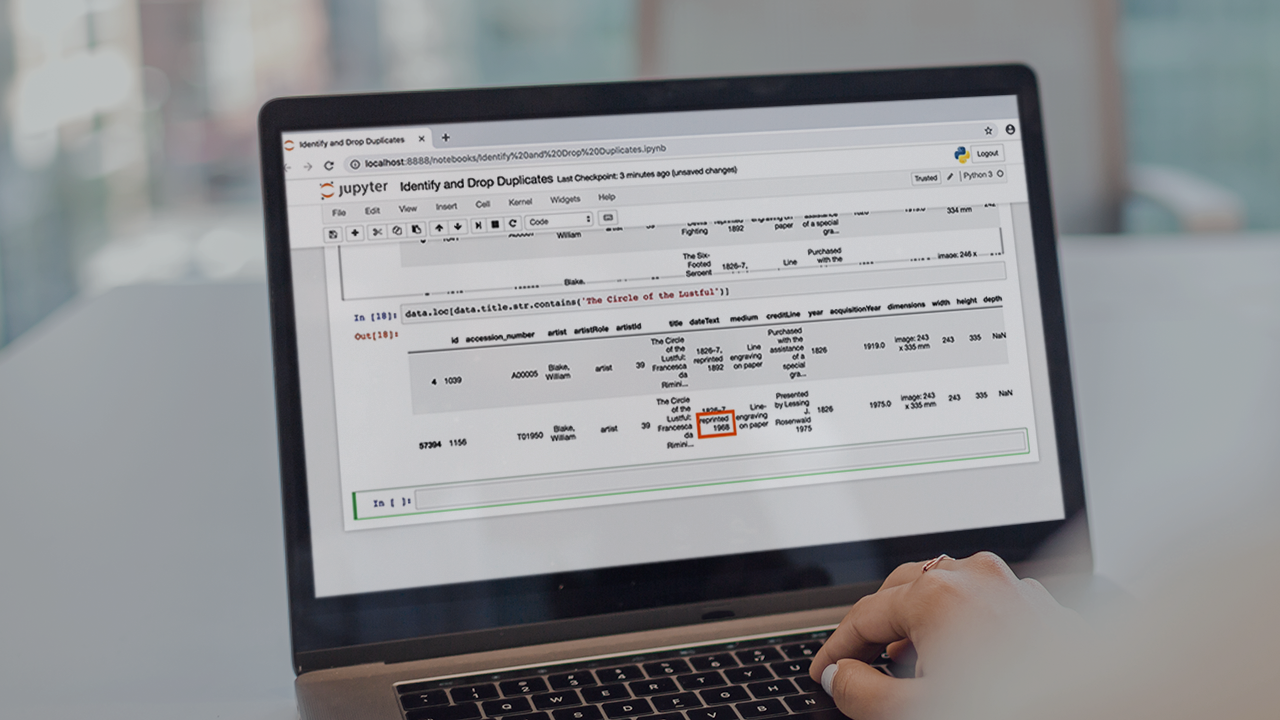
Cleaning the dataset is an essential part of any data project, but it can be challenging. This course will teach you the basics of cleaning datasets with pandas, and will teach you techniques that you can apply immediately in real world projects.
Beginner
- Course
Cleaning Data: Python Data Playbook
Cleaning the dataset is an essential part of any data project, but it can be challenging. This course will teach you the basics of cleaning datasets with pandas, and will teach you techniques that you can apply immediately in real world projects.
Beginner
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Data
What you'll learn
At the core of any successful project that involves a real world dataset is a thorough knowledge of how to clean that dataset from missing, bad, or inaccurate data. In this course, Cleaning Data: Python Data Playbook, you'll learn how to use pandas to clean a real world dataset. First, you'll learn how to understand, view, and explore the data you have. Next, you'll explore how to access just the data that you want to keep in your dataset. Finally, you'll discover different ways to handle bad and missing data. When you're finished with this course, you'll have a foundational knowledge of cleaning real world datasets with pandas that will help you as you move forward to working on real world data science or machine learning problems.
Cleaning Data: Python Data Playbook
Beginner
Chris is a software consultant focused on web, mobile, and machine learning. He uses React, React Native, Node.js, Ruby on Rails, and Python.
