
- Course
Building Features from Nominal and Numeric Data in Microsoft Azure
Applying statistical techniques to your data within Azure Machine Learning Service will often boost model performance. This course will teach you the basics of data cleansing, including basic syntax and functions.
Beginner
- Course
Building Features from Nominal and Numeric Data in Microsoft Azure
Applying statistical techniques to your data within Azure Machine Learning Service will often boost model performance. This course will teach you the basics of data cleansing, including basic syntax and functions.
Beginner
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- AI
- Cloud
What you'll learn
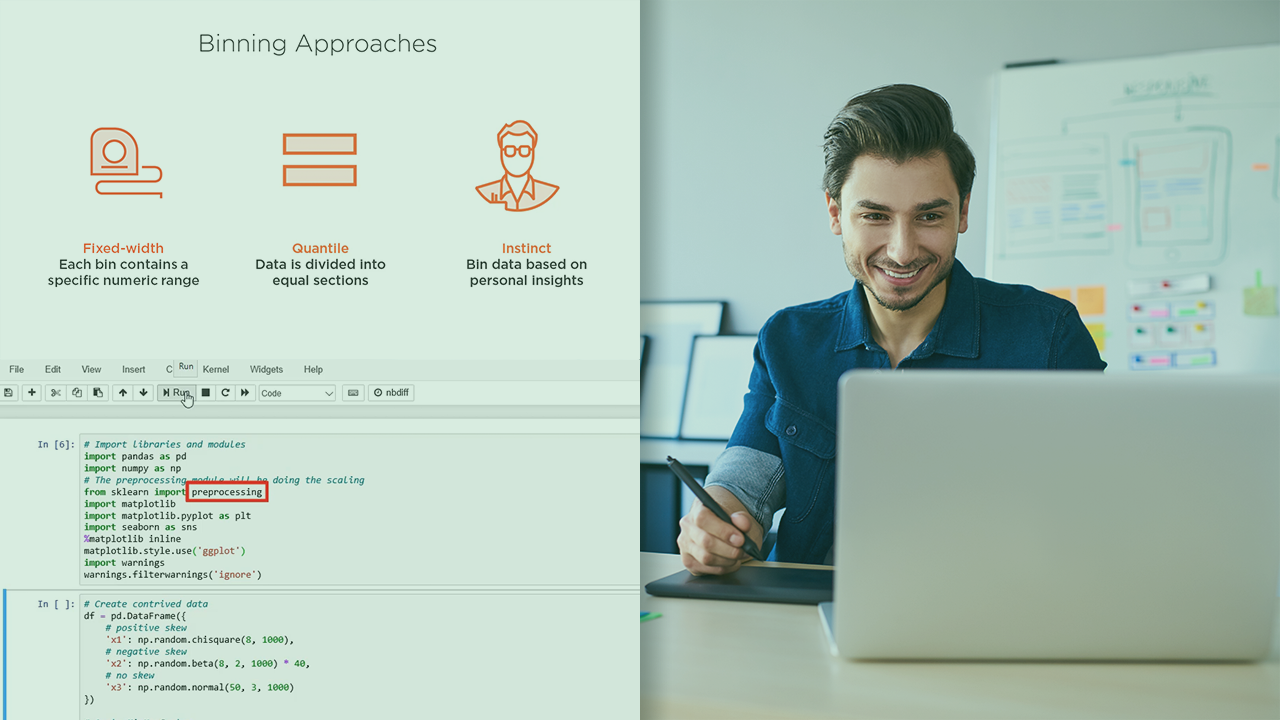
At the core of applied machine learning is data. In this course, Building Features from Nominal and Numeric Data in Microsoft Azure, you will learn how to cleanse data within the confines of Azure Machine Learning Service. First, you will discover the sundry options you have within Azure Machine Learning Service for building your models end to end. Next, you will explore the importance of applying statistical techniques to your data to improve model performance. Finally, you will learn how to apply various data cleansing techniques to your data for enhancing real-world performance. When you are finished with this course, you will have a foundational knowledge of Azure Machine Learning Service and a solid understating of how to apply statistical techniques to your data that will help you as you move forward to becoming a machine learning engineer.
Building Features from Nominal and Numeric Data in Microsoft Azure
Beginner
Table of contents
-
Module Overview | 2m 18s
-
Is This Course for You? | 1m 39s
-
Skills Recommended for This Course | 1m 28s
-
Measures of Central Tendency | 1m 43s
-
Measures of Variability | 2m 52s
-
Modality and Skewness | 2m 26s
-
Kurtosis | 1m 27s
-
Gaussian Distributions | 5m 5s
-
Calculating the Mean, Median, and Mode | 3m 15s
-
Summary | 2m 31s
Mike has Bachelor of Science degrees in Business and Psychology. He's passionate about machine learning and data engineering.
