
- Course
Implementing an Azure Databricks Environment in Microsoft Azure
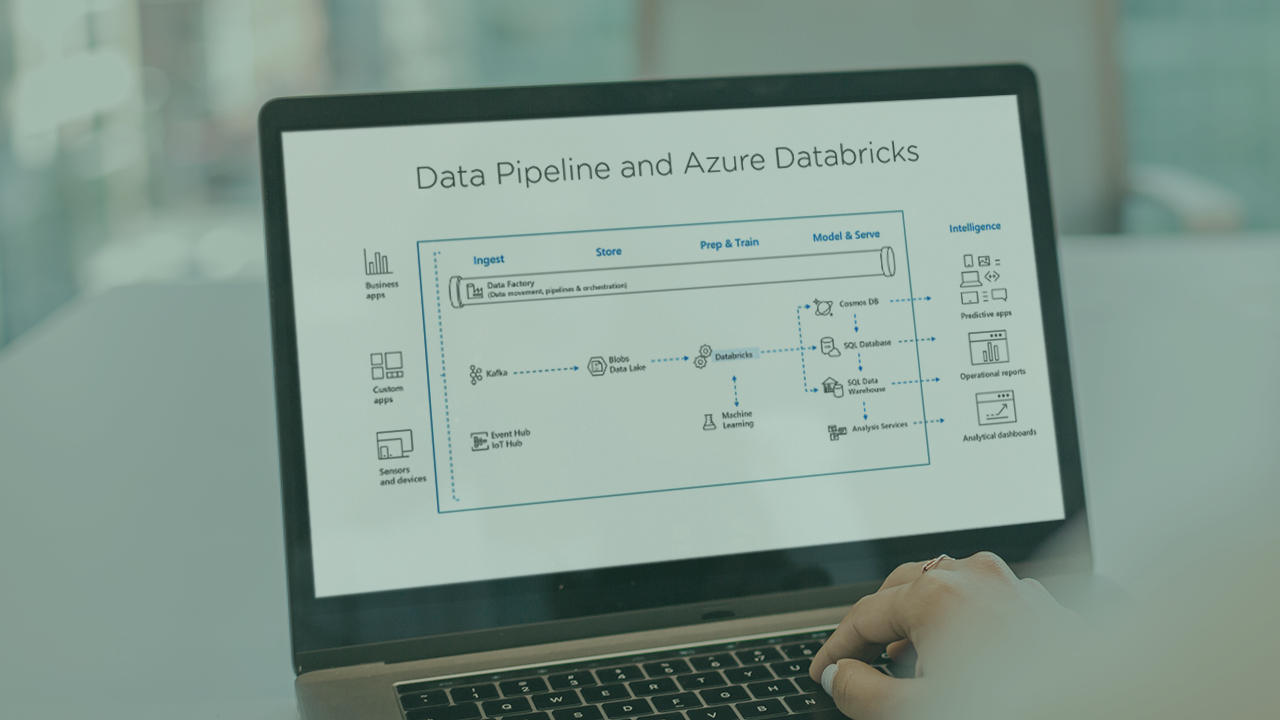
Everyday we have more data, and the problem is how do we get to where we can use the data. Learn how Azure Databricks helps solve those data problems with a robust analytics platform for bringing your data together for data engineers and scientists.
Advanced
- Course
Implementing an Azure Databricks Environment in Microsoft Azure
Everyday we have more data, and the problem is how do we get to where we can use the data. Learn how Azure Databricks helps solve those data problems with a robust analytics platform for bringing your data together for data engineers and scientists.
Advanced
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Cloud
- Data
What you'll learn
Every day, we have more and more data, and the problem is how do we get to where we can use the data for business needs. In this course, Implementing a Databricks Environment in Microsoft Azure, you will learn foundational knowledge and gain the ability to implement Azure Databricks for use by all your data consumers like business users and data scientists. First, you'll learn the basics of Azure Databricks and how to implement ts components. Next, you will discover how to work with Azure Databricks during ETL (Extract, Transform, Load) operations. Then, you'll move on to performing batch scoring with machine learning models. Finally, you will explore how to work with streaming data from HDInsight Kafka. When you’re finished with this course, you will have the skills and knowledge of Azure Databricks needed to implement data pipeline solutions for your data consumers. Software required: Microsoft Azure Subscription
Implementing an Azure Databricks Environment in Microsoft Azure
Advanced
Table of contents
-
Overview | 2m 39s
-
Introduction to Azure Databricks | 6m 40s
-
Fundamentals of Azure Databricks | 2m 40s
-
Creating an Azure Databricks Workspace | 7m 4s
-
Getting Started with the Databricks CLI | 4m 24s
-
Azure Spark Clusters | 6m 30s
-
Notebooks | 5m 3s
-
Azure Databricks Tables | 3m 56s
-
Apache Spark Jobs | 5m 49s
-
Summary | 2m 2s
Michael is a six-time Microsoft Most Valuable Professional, author, technical trainer, and community leader. Having been in the IT industry since the 90's, his experiences covers the gamut of Microsoft technologies, with his main focus being Windows Server, PowerShell and cloud technologies like AWS and Azure. Along with training, he has a passion for connecting people and building community in the IT Pro space. He is the current president and a founding member of The Krewe User Groups, Inc., a world-wide networking group for IT Pros and Developers.
