
- Course
Scalable Data Processing with Python
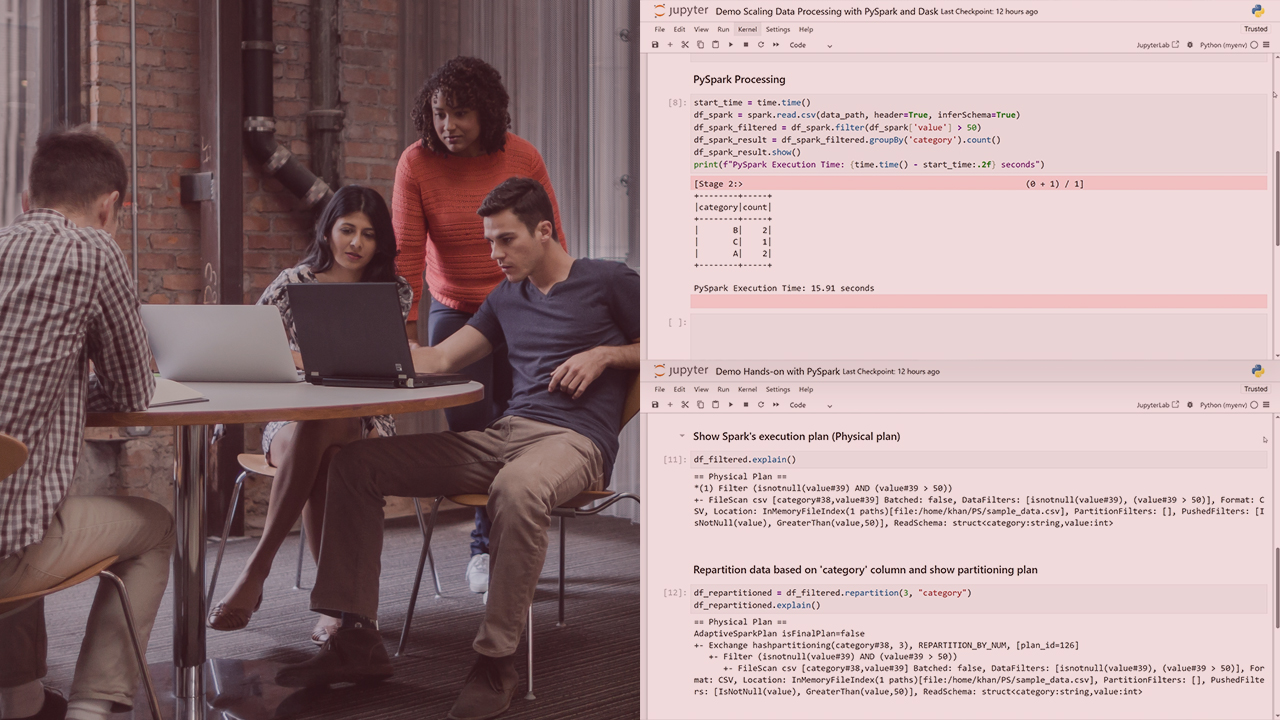
Learn to process large-scale data efficiently with Python. This course will teach you to leverage PySpark and Dask for scalable, parallel, and distributed data processing, and to optimize performance and handle real-world scaling challenges.
Intermediate
- Course
Scalable Data Processing with Python
Learn to process large-scale data efficiently with Python. This course will teach you to leverage PySpark and Dask for scalable, parallel, and distributed data processing, and to optimize performance and handle real-world scaling challenges.
Intermediate
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Data
What you'll learn
Scalable data processing is essential for handling large datasets efficiently, yet many struggle with optimizing performance.
In this course, Scalable Data Processing with Python, you’ll gain the ability to process and manage large-scale data using PySpark and Dask.
First, you’ll explore the fundamentals of scalability, including parallel, distributed, and batch processing.
Next, you’ll discover how to use PySpark to process massive datasets with transformations, caching, and optimizations.
Finally, you’ll learn how to leverage Dask for parallel computation, optimizing execution with task graphs and lazy evaluation.
When you’re finished with this course, you’ll have the skills and knowledge to efficiently process large datasets and handle performance challenges in scalable data processing.
Scalable Data Processing with Python
Intermediate
Table of contents
Dr. Yasir Khan is a global tech consultant and 38Labs founder. He's passionate about digital transformation, data & AI, and regularly shares technology insights on Pluralsight.
