
- Course
Real World Big Data in Azure
The Big Data components of Azure let you build solutions which can process billions of events, using technologies you already know. In this course, we build a real world Big Data solution in two phases, starting with just .NET technologies and then adding Hadoop tools.
Intermediate
- Course
Real World Big Data in Azure
The Big Data components of Azure let you build solutions which can process billions of events, using technologies you already know. In this course, we build a real world Big Data solution in two phases, starting with just .NET technologies and then adding Hadoop tools.
Intermediate
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Cloud
What you'll learn
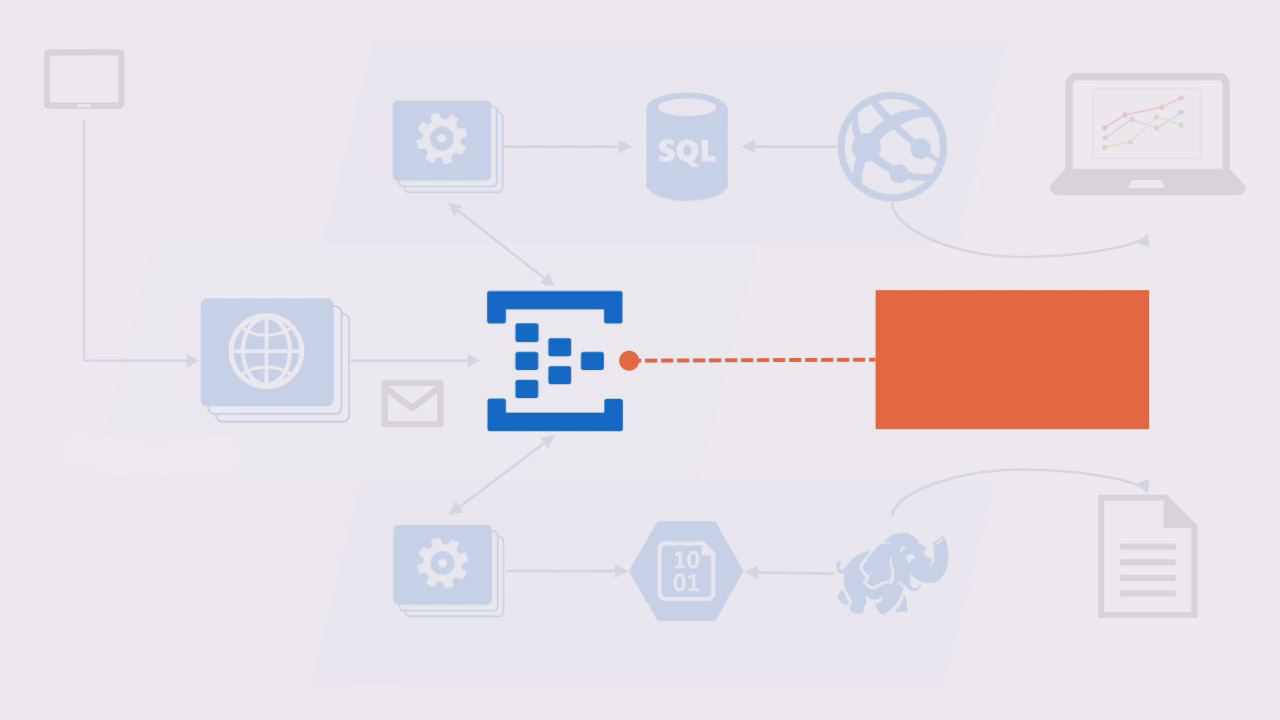
How do you make sense of Big Data? When you’re receiving 100 million events per hour and you need to save them all permanently, but also process key metrics to show real-time dashboards, what technologies and platforms can you use? This course answers those questions using Microsoft Azure, .NET, and Hadoop technologies: Event Hubs, Cloud Services, Web Apps, Blob Storage, SQL Azure, and HDInsight. We build a real solution that can process ten billion events every month, store them for permanent access, and distill key streams of data into powerful real-time visualizations.
Real World Big Data in Azure
Intermediate
Table of contents
-
Introducing Big Data in Azure | 2m 20s
-
Is This Course for Me? | 1m 36s
-
Building the Phase 1 Solution | 2m 43s
-
Evolving the Phase 2 Solution | 2m 44s
-
Introducing the Telemetry API | 1m 53s
-
Demo: EventsController | 4m 13s
-
Key Features of the Telemetry API | 2m 41s
-
Zipping the Event Batch | 2m 20s
-
Demo: GZipToJsonHandler | 5m 2s
-
Testing the API | 1m 53s
-
Demo: IEventSender | 3m 45s
-
Module Summary | 3m 6s
-
Module Introduction | 1m 39s
-
Introducing Event Hubs | 1m 52s
-
Configuring Event Hubs | 3m
-
Creating Event Hubs | 3m 29s
-
Automating Event Hub Creation | 2m 58s
-
Sending Events | 3m 17s
-
Demo: EventHubEventSender | 3m 39s
-
Batching Events | 3m 13s
-
Demo: EventBatchIterator | 4m 4s
-
Batching and Testing | 2m 19s
-
Demo: Acceptance Tests | 2m 51s
-
Understanding Throughput Units | 3m 50s
-
Demo: Deploy, Monitor & Scale | 3m 33s
-
Next Steps for Deployment & Monitoring | 2m 11s
-
Isolating the Event Hub | 2m 22s
-
Module Summary | 2m 34s
Elton is an independent consultant specializing in systems integration with the Microsoft stack. He is a Microsoft MVP, blogger, and practicing Technical Architect.
