
- Course
Web Scraping: Python Data Playbook
Learn how to tell a compelling graphical data story in a Jupyter Notebook with Seaborn having scraped information from a static web page with BeautifulSoup4 when no API is available.
Beginner
- Course
Web Scraping: Python Data Playbook
Learn how to tell a compelling graphical data story in a Jupyter Notebook with Seaborn having scraped information from a static web page with BeautifulSoup4 when no API is available.
Beginner
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Data
What you'll learn
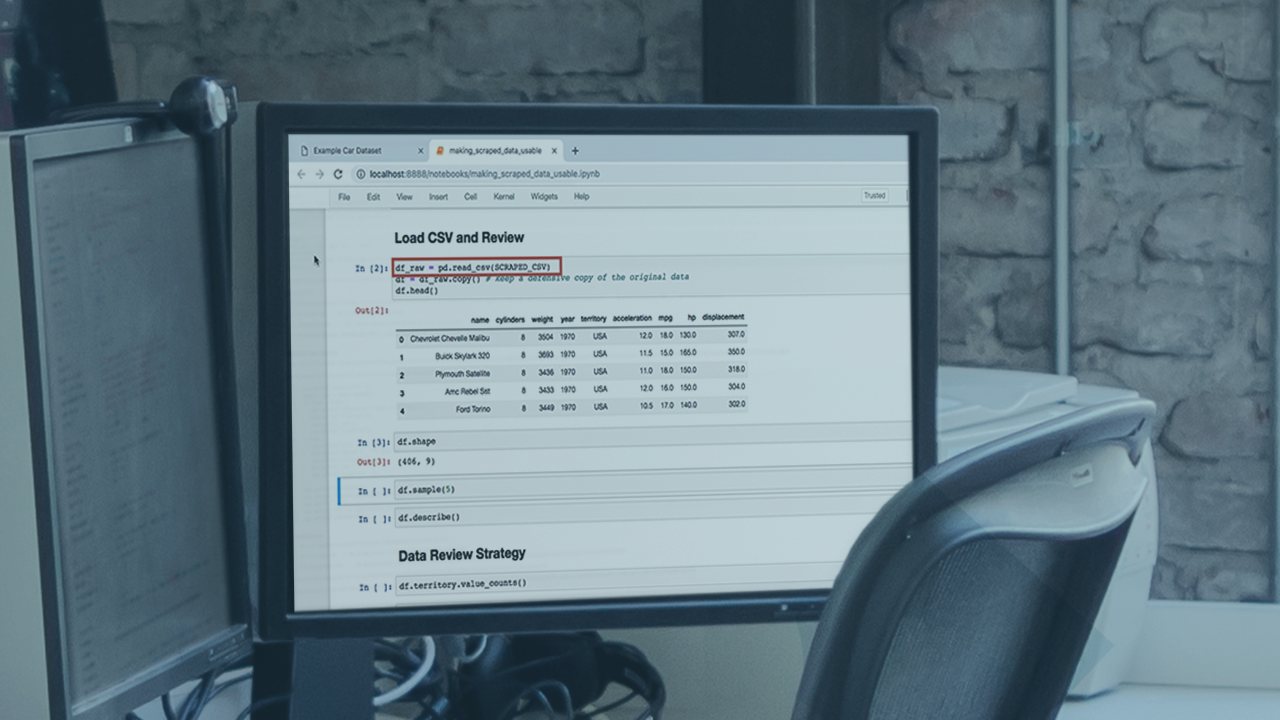
Scrape data from a static web page with BeautifulSoup4 and turn it into a compelling graphical data story in a Jupyter Notebook. In this course, Web Scraping: The Python Data Playbook, you will gain the ability to scrape data and present it graphically. First, you will learn to scrape using the requests module and BeautifulSoup4. Next, you will discover how to write a trustworthy scraping module backed by a unit test. Finally, you will explore how to turn the columns of data in a graphical story that will change the opinions of your colleagues. When you're finished with this course, you will have the skills and knowledge of web scraping needed to create a graphically compelling Jupyter Notebook without the use of an API.
Web Scraping: Python Data Playbook
Beginner
Ian is an Interim Chief Data Scientist and Coach, he co-organises the annual PyDataLondon conference with 700+ attendees and the associated 9,500+ member monthly meetup. With 16 years experience he runs Mor Consulting in London, speaks internationally often as keynote speaker and is the author of the bestselling O'Reilly book High Performance Python. For fun he's walked by his high-energy Springer Spaniel, surfs the Cornish coast and drinks fine coffee.
