
- Course
Processing Data on AWS
This course will teach you the fundamentals of data processing with AWS. This topic is the most important domain of the AWS Certified Data Analytics specialty certification (24%, according to the official DAS-C01 Exam Guide.)
Intermediate
- Course
Processing Data on AWS
This course will teach you the fundamentals of data processing with AWS. This topic is the most important domain of the AWS Certified Data Analytics specialty certification (24%, according to the official DAS-C01 Exam Guide.)
Intermediate
Get started today
Access this course and other top-rated tech content with one of our business plans.
Try this course for free
Access this course and other top-rated tech content with one of our individual plans.
This course is included in the libraries shown below:
- Cloud
- Data
What you'll learn
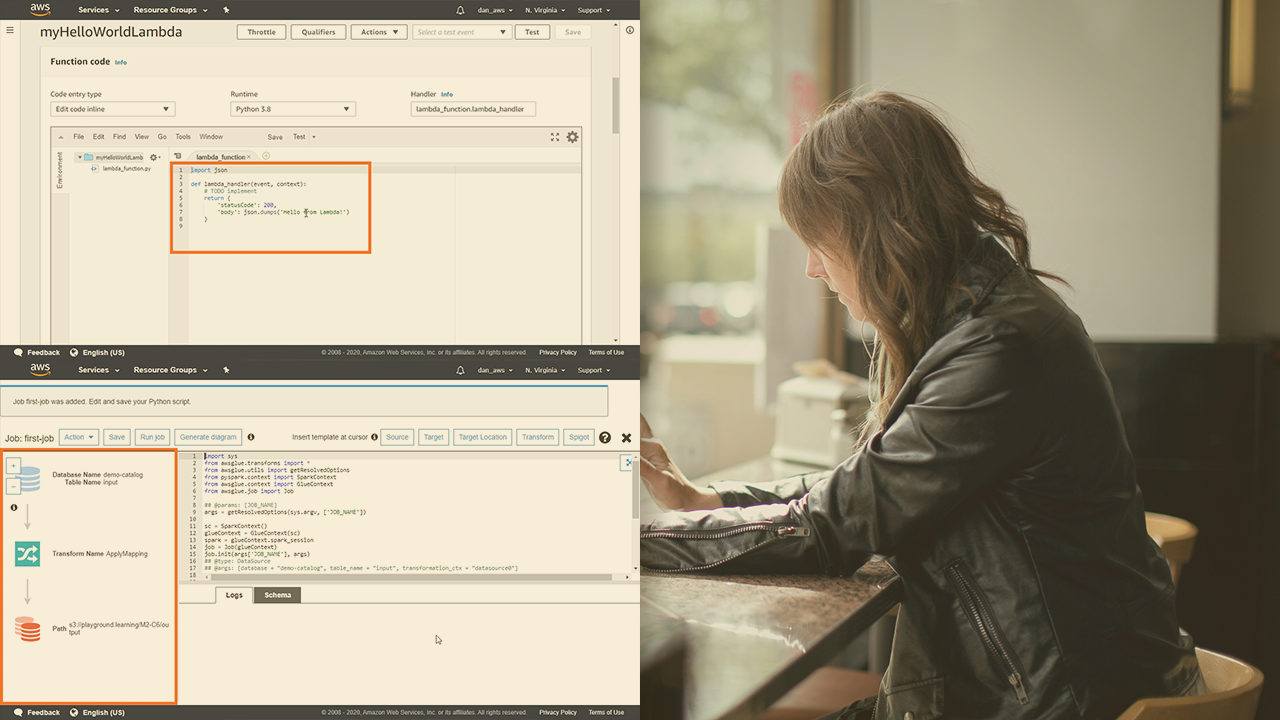
Learning the fundamentals of data processing with AWS is not as difficult as it may seem. In this course, Processing Data on AWS, you will learn how to process large amounts of data on AWS. First, you’ll explore data processing with Lambda and Glue. Next, you’ll discover the basics of the Hadoop ecosystem and how to use it with AWS EMR. Finally, you’ll learn how to automate data processing using AWS Data Pipeline. When you’re finished with this course, you’ll have the skills and knowledge of the AWS services needed to process large amounts of data on AWS and get certified in it.
Processing Data on AWS
Intermediate
As a software engineer and lifelong learner, Dan wrote a PhD thesis and many highly-cited publications on decision making and knowledge acquisition in software architecture. Dan used Microsoft technologies for many years, but moved gradually to Python, Linux and AWS to gain different perspectives of the computing world.
